

数据挖掘工具包和要点
简要介绍数据采集所需的材料、使用 Python 和软件进行采集时可能需要的材料以及不需要的材料。
数据搜刮是任何人从特定网站获取大量数据的最佳捷径。术语 "数据搜刮 "包括使用"......"。爬虫,"它可以从一个网页导航到另一个网页,甚至在一个网页中导航到另一个子网页;'蜘蛛在网站所有者认为法律允许的范围内提取数据",以及 "在网站所有者认为法律允许的范围内提取数据"。刮板这可能指的是让机器为你收集和存储数据的整个功能。
我们所说的数据并不是一两个 html 文件:刮擦器可以在短时间内提取数百万个数据点。更妙的是,它们可以根据指令专门提取所需的数据类型。在许多情况下,这就是建立海量数据集的方法:人类收集数据的速度和效率远不及机器。这就是人们所说的数据挖掘的本质。
但首先要知道,任何一台个人电脑的数据搜刮能力都是有限的。要想在工业级水平上进行数据搜刮,需要服务器和数据中心的计算能力。这也是为什么下面列出的许多服务都有定价选项。对于那些没有定价选项的服务,障碍来自于
数据挖掘协议
无论您使用什么工具进行数据搜刮,网站都会制定一些习惯性协议。不遵守这些协议可能会带来一些不同的负面结果。如果网站规模较小,大量的数据搜刮可能会对其服务器造成影响,从而被视为服务器攻击,这可能会产生法律后果。中型或大型网站不太容易受到这种影响,但也会产生其他后果。
如果不遵守网站规定的规则,你的 IP 地址可能很快就会被封禁。如果网站有 API,则鼓励使用 API。但 "搜刮 "更多的是从网页中提取原始数据,因此使用 API 在技术上是用一种完全不同的方法收集数据。在任何情况下,你可以刮取的内容、刮取的频率以及刮取内容的大小都是有限制的。当你了解了数据搜刮后,你可能会熟悉 "工人 "或 "蜘蛛"(稍后定义)这些术语。这些都需要遵循这些准则,但在哪里可以找到这些准则呢?
"/robots.txt"。
只要单一域名下的网页网络中存在信息,较大的网站通常都会有一个登陆页面,说明数据刮擦器能在其网站上做什么和不能做什么。这些信息通常可以在主页的 URL 下找到,后面跟着"/robots.txt"。
例如,以限制比同行多而著称的社交媒体网络 Facebook,在其网站上标记了所有被禁止的行为。 facebook.com/robots.txt.下面是直接从他们自己的 "robots.txt "子页面上截取的一些他们不允许您搜刮的内容。这里也是检查网站是否包含网站地图的好地方。有的网站有,有的网站没有,但如果有,搜刮者的工作就容易多了。
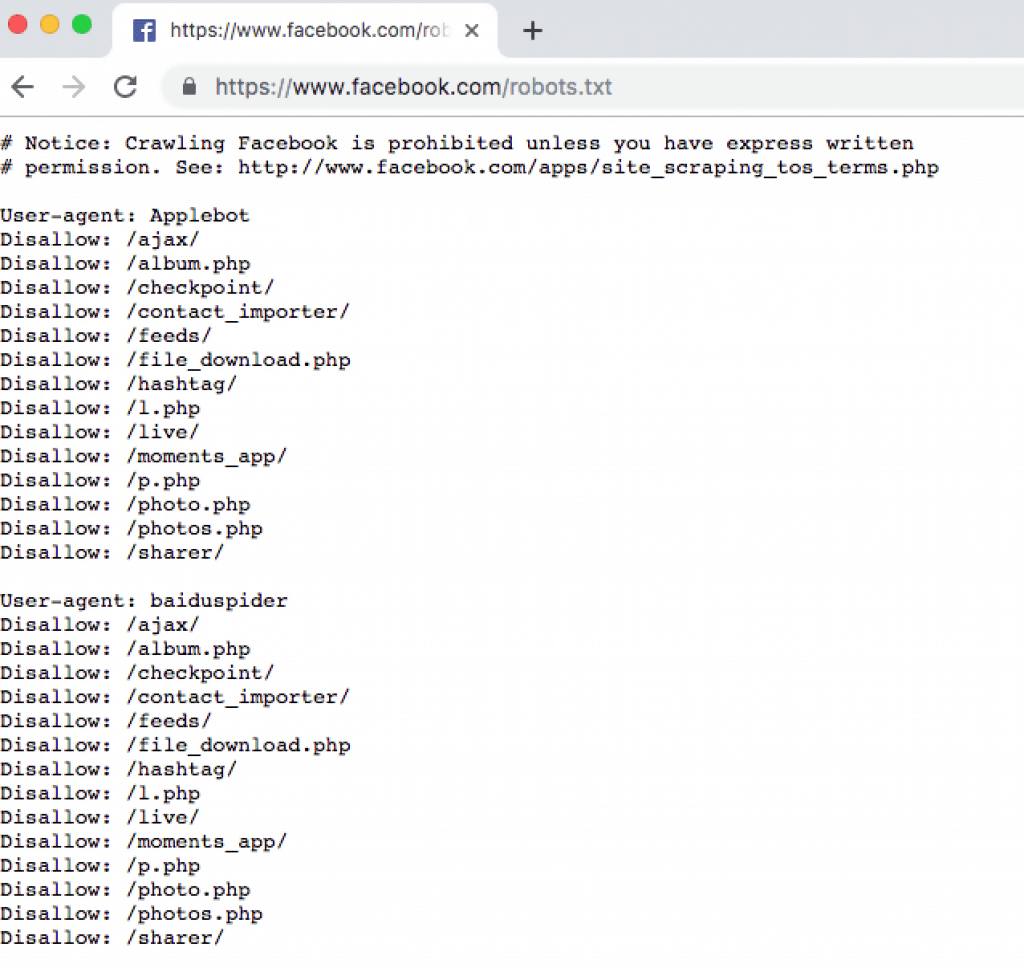
请注意,这并不意味着从该特定网站(或从任何网站)搜刮此类数据是不可能的。这只是意味着管理员在很多方面增加了难度:更容易被禁止 IP,更难使用简单、流行的网络搜刮工具,以及其他障碍。当然,只要有一定的编程能力,这些问题总能在一定程度上被规避。
使用 Python 浏览
无论如何,我想下面的前两个软件包已经融入了 Python 的大多数网络搜索工作中。它们配合得天衣无缝,都为网络搜索提供了宝贵的任务。
美丽汤
Beautiful Soup(可通过 pip 或 conda 安装为 "bs4")是一个非常有用的数据搜刮软件包。它之所以有用,是因为它可以轻松地处理刮取的数据,从典型的网页中提取出需要的内容,剔除不需要的内容。
当工人们从一个机位爬到另一个机位提取数据时,他们需要得到下载内容的指示。如果没有指令,他们就会下载全部内容,这样做效率太低、太笨重、太吵闹,根本不实用。
因此,"美丽汤 "可以告诉搜索工具从网页中提取哪些特定的数据点,例如,表格中某一列的单元格内的条目。
对于那些有 Python 使用经验并想根据自己的喜好用 Beautiful Soup 编写脚本的人来说,其他地方有更好的教程。(插入超链接)。不过,对于 HTML/CSS/JS 网页上的常见提取,也有许多脚本是公开可用的。
要求
如果您已经在使用 Python,那么您很可能已经安装了 "请求"。如果还没有,请立即安装,因为它的用处非常大,甚至超出了本主题的范围。简而言之,"请求 "允许您以多种有用而灵活的方式与网页交互。Requests 可以与网页交互,抓取某个网页的整个网站地图,甚至在提示时登录,因为 Beautiful Soup 会提取必要的数据。它是脚本在互联网上的导游:带它去需要去的地方,允许它访问自己无法访问的地方,并根据需要从一个地方移动到另一个地方,同时提供网站和网站地图的信息。
包裹
该包裹在功能上与 "美丽汤 "类似,都具有数据搜刮功能。简单地说,它能像 Beautiful Soup 一样,将刮擦器导向它想要的数据。它的优势在于可以自动浏览 XPath 和其他常见的 CSS 容器,因为这些容器通常会隐藏数据。
Beautiful Soup 也可以做到这一点,不过,在编写 Beautiful Soup 脚本时,必须让 Beautiful Soup 知道在哪里可以找到隐藏在 Xpath 中的数据。
您只需在网页上的 Xpath 中找到一个数据示例,但这需要右键单击页面,单击 "检查元素",然后查看 div,以便找到隐藏在其中的数据示例。下面是我写的一个脚本示例,实际上我必须使用 Selenium(稍后讨论):
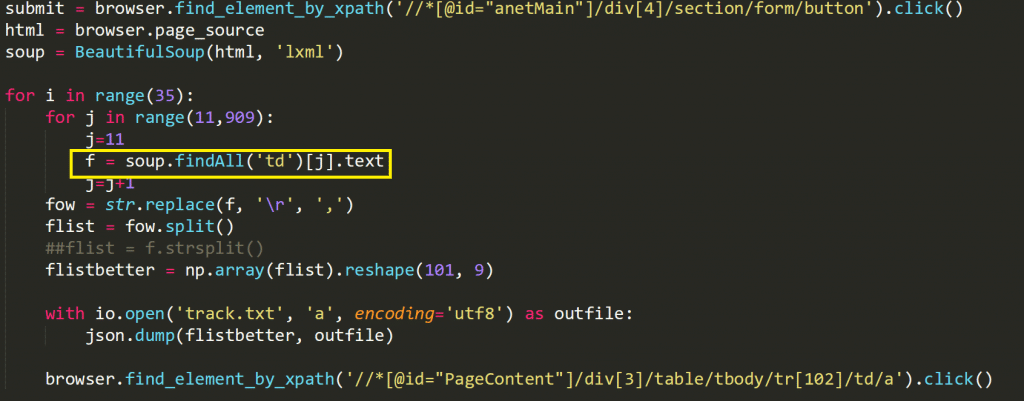
td "是数据隐藏在 Xpath "tr "下的地方。一旦我找到了,剩下的就交给汤了。
不过,Parcel 可以跳过首先找到元素的步骤,因为它可以自己找到元素,如下所示 的部分.看起来必然的情况是,这个软件包比 Beautiful Soup 更笨重,可能会导致运行速度变慢,但它提供了更多的功能。
虽然《美丽汤》也相当简单,但它可能更适合初学者。两个都试试,看看哪个适合你。但对于初学者来说 这里是 一个使用请求和 Parcel 的公开爬虫演示。
更好的办法是 这里是 网站上有许多使用 Parcel 脚本的链接,并对 Parcel 进行了解释。由于 "美汤 "已经存在了很长时间,因此没有像这里一样有那么多现成的分配脚本。
JSON
JSON 作为 Python 软件包可能是保存受惊数据的最有效方法。无处不在的 "pandas "包提供了相同的功能,在此也值得一提。使用内置的 "re "包,脚本需要将刮擦到的数据写入一个文件,并将该文件保存在计算机上的某个位置。
Selenium
Selenium 既笨拙又低效,但如果网页的编写方式是前面提到的程序无法理解的,它就能发挥重要作用。Selenium 并非任何类型的搜索器,但在紧要关头可用于将搜索器导航到它需要去的地方。Selenium 是一个浓缩在 Python 软件包中的网络浏览器。
它需要一个驱动程序,通常是一个 ChromeDriver,它将使用谷歌 Chrome 浏览器。这意味着,当您使用硒运行脚本时,您选择的浏览器会自动打开,它可以自行点击页面的某些部分、在某些表单中输入按键等。
它看起来很酷,但对于网络搜刮来说,它的主要目的是将网络搜刮器导航到网页上所需数据所在的特定区域。这是一种 "如果全部失败,那么其他全部失败 "的机制,因为上述软件包可以处理绝大多数网页。
Scrapy
许多这类工具的问题是使用起来很麻烦。Scrapy 需要 Visual Studio 14.0,你可以通过下载 Visual Studio Build Tools 获得。像这样的扩展要求会增加遇到困难的几率。
编程环境、每个软件包以及您使用的机器或服务器的具体情况都会影响兼容性。不过请注意,Mac 和 Linux 在使用 PyPi 下载 Scrapy 时不会有问题。如果你不熟悉这个过程,下面是你的终端应该显示的样子:
利用Scrapy内置的抓取和数据整理工具的脚本在Github、Stackoverflow和公共资源上随处可见。其中许多脚本,事实上是大多数脚本,可能并不像开箱即从终端运行那么简单。因此,对于非程序员或处于休眠期的程序员来说,这些软件可以派上用场、
使用软件扫描
有几种不同类型的 数据搜刮软件工具 有的需要一点编程知识,有的则完全不需要。有些需要一点编程知识,有些则完全不需要。
有些工具比其他工具具有更强的功能(例如,扫描多媒体,即 PDF、图像、音频和视频文件)。下面我们就来介绍几种比较流行的工具。
橙色
免费数据挖掘网站 Orange 发现 这里 以及 Github 上的工具,是我个人最喜欢的从 Twitter 等特定网站抓取内容的工具。
它的主菜单是一个可视化路线图,你将在其中构建和实施整个流程。下面是我所做的一个数据挖掘项目的工作流程示例,旨在说明该软件的组织能力。
使用 Orange 进行数据搜刮有几个好处。首先,存储、处理和保存数据变得异常简单。简短翔实的试用版公开提供如何操作的说明。软件必须遵守第三方的条件条款,这对网络搜索来说是个负担。例如,在搜索 Twitter 时,您需要一个 API 密钥--了解如何获得该密钥 这里 (任何人都可以获得一个),但使用 API 会限制在一定时间内允许搜索的数据量。另一方面,Orange 的优势在于允许用户在工作流程中执行任何脚本,因此上文提到的所有内容都可以整合到 Orange 中。
在软件中,你可以找到一个下载扩展的选项,其中包括一个数据搜刮扩展。完成下载后,将小工具添加到工作流程中就能轻松完成数据采集。
Octoparse
Octoparse 是一款基本免费的网络搜索软件,适用于所有主流操作系统。由于它为有能力的行业提供高级软件包,因此该软件的功能非常出色。与其他只提供非常非常有限的免费搜索功能的软件不同,Octoparse 为免费用户提供了丰厚的套餐:每次抓取不限页面、每次使用 10 个爬虫、每次导出 10,000 条记录。记录数量是免费计划的关键限制:根据不同的项目,10,000 条记录可能绰绰有余,也可能远远不够。
无论如何,它与上面列出的 Python 软件包一样有效,甚至可能更有效。它们的 产品概述 并不夸大其能力。只是要注意其局限性。
付费铲运机
有一种网络搜刮软件很容易找到,但却不容易让人舍得花钱购买。这些软件适合企业使用。Import.io、Mozenda 和 Helium 都获得了好评,但价格都不菲。由于我没有使用它们的经验,所以我不会介绍它们,但选择权在你。只需知道它们就在那里。
请注意:100% 免费数据抓取软件几乎从未兑现过承诺!
最专业、最苛刻、最有效的数据搜刮方法是使用具有高计算能力的服务器或 GPU 的机器,使用手工编程的脚本进行数据搜刮。现在有数以百计的数据搜索程序,只需在 Sourceforge 上快速搜索一下即可:
如果这些软件的功能看起来不切实际,那么它们很可能就是不切实际的。一定要检查软件是否有健康、最新的更新,评论是否支持开发者所说的软件功能,以及每周的下载量是否健康。这些不符合这些标准的程序可能没有恶意,但它们可能只是垃圾。
因此,粗略地说,数据搜刮有两种途径。编程、脚本路线,它提供了更多的自由、更多的个性化和更多的定制。然后是软件路线,它提供了易用性和额外的计算能力。无论哪种选择,其可行性都取决于希望编程的数量与希望自掏腰包的数量。正如前面所讨论的,对于真正有效的网络搜索软件来说,这种情况是不可避免的。
