

使用Praw和Python爬取Reddit - 详细操作步骤
无论你对 Reddit 在集体意识中的作用是爱是恨,但不可否认的是,Reddit 包含了大量难以理解的数据,而这些数据在很多方面都很有价值。仅数据集子页面本身就是一个数据宝库,但即使不是专门用于数据的子页面也包含大量数据。
因此,在某些时候,许多网络刮擦工具会希望抓取和/或刮擦 Reddit 的数据,无论是用于主题建模、情感分析,还是其他任何数据在当今时代变得如此有价值的原因。从 Reddit 搜刮数据仍然是可行的,Reddit 甚至鼓励这样做,但也存在一些限制,这使得从 Reddit 搜刮数据比从其他网站搜刮数据更令人头疼。
Reddit 增加了搜索难度!原因如下
过去,从 Reddit 上抓取任何东西都很简单,只需使用 Scrapy 和一个 Python 脚本 以在单个 IP 地址允许的范围内提取尽可能多的数据。这是因为,如果你看一下最后一句话中的指南链接,其中的诀窍就是根据页码在 Reddit 的子域中逐页抓取。
当一页上的所有信息都收集完毕后,脚本就知道该进入下一页了。这就是为什么脚本中的基本 URL 会以 "pagenumber="结尾,留出空白供蜘蛛浏览页面。
现在情况发生了变化。页码已被无限滚动所取代,它催眠了无数网民,让他们无休止地搜索新鲜内容。幸运的是,Reddit 的 API 易于使用,易于设置,对于普通用户来说,24 小时内抓取的数据绰绰有余。下面,我将为每个人,即使是从未编写过代码的人,提供逐步说明。
获取 Python 并在此过程中不弄乱任何东西
下面,我们将向从未使用过任何形式代码的人讲解如何使用 Python 搜刮 Reddit 和亚马逊评论数据。熟悉代码的人会知道哪些部分可以跳过,比如安装和入门。
对于初次使用 Python 的用户来说,一件小事就可能把整个 Python 环境搞得一团糟。因此,为了安全起见,如果您不知道自己在做什么,该怎么做?
获取 Python
- 下载并安装 Python.点击该链接后,您将看到一系列不同版本 Python 的下载选项。为此,最好选择最新版本。点击顶部的下载链接。
- 向下滚动所有关于 "PEP "的内容,现在这些都不重要。到达副标题 "PEP"。文件'.
- 对于 Mac,这将会更容易一些。如果不确定电脑是 32 位还是 64 位,只需点击 32 位链接。如果知道是 64 位,则点击 64 位。双击 pkg 文件夹,就像双击其他程序一样。跳转到下一节。
- Windows 用户最好选择写有 "可执行安装程序 "的版本,这样就无需构建过程。同样,只有当你知道你的电脑是 64 位电脑时,才点击版本说明中的 64。你应该点击"为了安全起见,使用基于 Web 的 Windows x86 安装程序。 下载完成后,双击 .exe 文件。
安装 Python
同样,这也不是 最好的 安装 Python 的方法;这是安装 Python 的方法,以确保第一次安装不会出错。最终,如果您了解了用户环境和路径(对于 Windows 来说要复杂得多--Windows 用户,玩得开心点),以后再想办法吧。
下面是它将显示的内容。我们需要的选项在下图中。这个路径(为了安全起见我涂黑的部分)并不重要;如果一切顺利,我们以后就不需要找到它了。 确保将 Python 添加到 PATH。
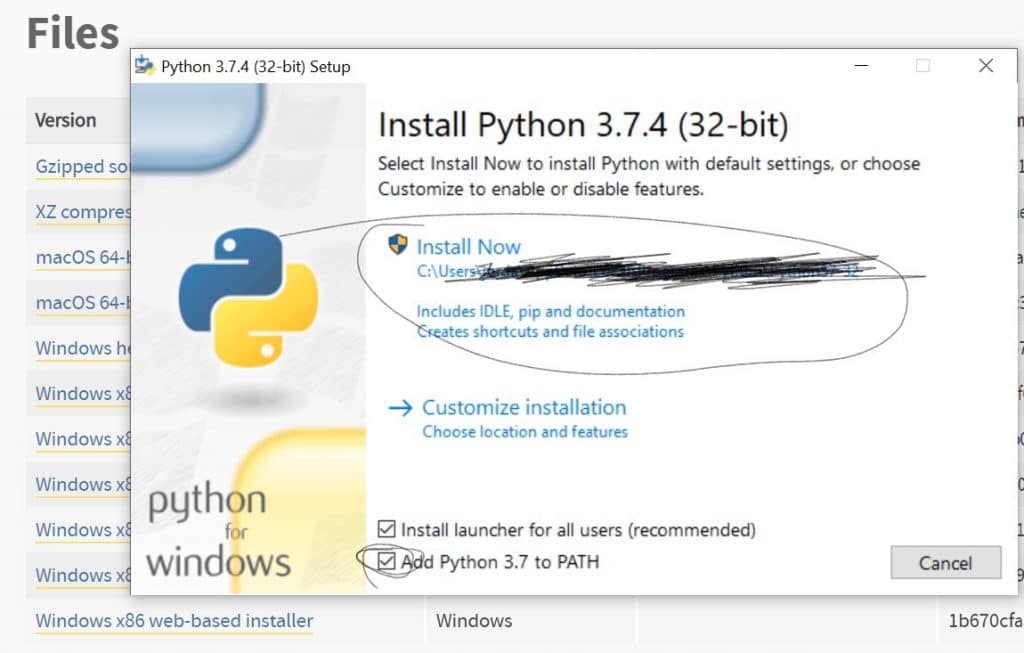
我不会在这里解释原因,但这是最安全的方法。 点击 "立即安装 "就可以了。现在我们有 Python 了。耶你可能会
进入命令提示符/终端
- Mac 用户:在 "应用程序 "或 "启动盘 "下找到 "实用工具"。然后找到终端。加载后,输入 "python",然后按回车键。如果没有,说明出了问题。输入 "Exit()",不加引号,然后按回车键,就这样。
- Windows:对于 Windows 10,可以按住 Windows 键,然后按 "X"。然后选择 "命令提示符"(不是管理员命令提示符,如果它不能正常工作,请使用它,但它应该能正常工作)。同样:输入 "python",然后按回车键。如果出现 "无法识别为 .... "的提示,你就成功了,输入 "exit() "并回车(这两个都不用引号)。
- 如果这一步出了问题,请先尝试重启。然后,我们将继续前进,抱歉。
Pip
我们需要 pip 中的一些功能,幸运的是,我们在安装 python 时都安装了 pip。Mac 和 Windows 用户都要键入以下内容:
pip install praw pandas ipython bs4 selenium scrapy
一些先决条件应该和我们需要的东西一起自行安装。对于 Reddit 搜刮,我们只需要前两个:它需要在某处显示 "prew/pandas 已成功安装"。Scrapy 可能无法工作,我们现在可以继续。如果这段代码没有任何反应,那就试试看:
python -m pip install praw' ENTER、'python -m pip install pandas' ENTER、'python -m pip install ipython' ENTER。
暂时最小化该窗口。我们将在获得 API 密钥后再返回该窗口。
获取 Reddit API
您只需要一个 Reddit 账户和一个经过验证的电子邮件地址。
然后,你可以在 Google 上搜索 Reddit API 密钥,或直接点击此链接。向下滚动条款,直到看到所需表格。
公司名称和公司联系人可以随意填写。POC 电子邮件应该是您注册账户时使用的电子邮件。
在 "Reddit API 用例 "下,你几乎可以写任何你想写的内容。在 "开发者平台 "下选择一个即可。
与任何编程过程一样,即使是这个子步骤也涉及多个步骤。首先要通过 Reddit 应用程序接口的用户身份验证;由于上文提到的原因,用其他方式搜索 Reddit 要么行不通,要么无效。
你所说的应用程序的主要用途似乎并不重要,但对 "脚本 "选项的警告表明,选择该选项可能会带来不必要的限制。第一个选项--不是手机应用程序,但也不是脚本--是任何相关方期望从中得到的最诚实的东西。
确保将重定向 URI 设置为 http://localhost:8080.这就是刮擦数据的来源。您可以在搜刮过程中通过浏览器进入该页面,观看搜刮过程。
让我们从这个开始,看看它是否有效。然后,我们可以查看 API 文档,看看还能从网站上的帖子中提取什么。
现在,'OAUTH 客户端 ID *"是一个需要额外步骤的选项。点击旁边的链接 登录账户。
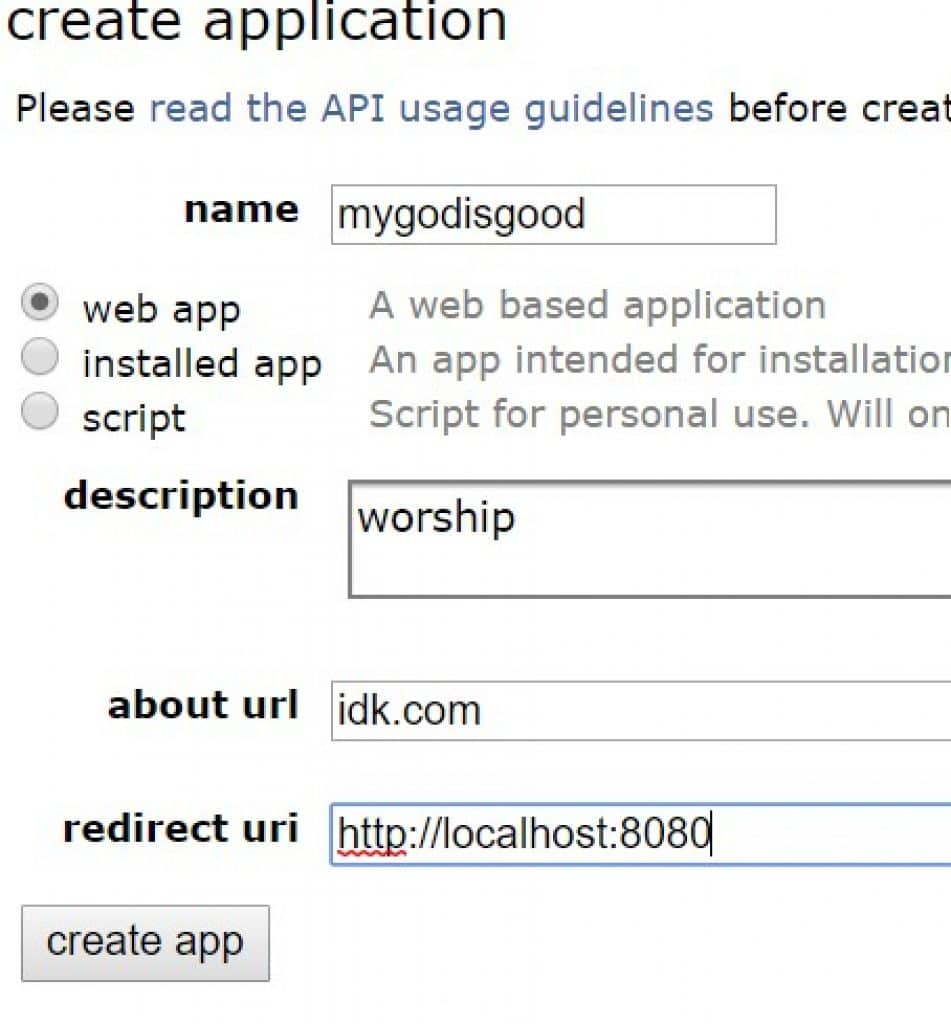
- 姓名:随你输入(我建议不要使用粗俗语言等)。
- 描述: 在键盘上输入任意字母组合 "agsuldybgliasdg"。
- SELECT 'web app
- 关于网址:任何内容
- 重定向 uri: ' http://localhost:8080 '
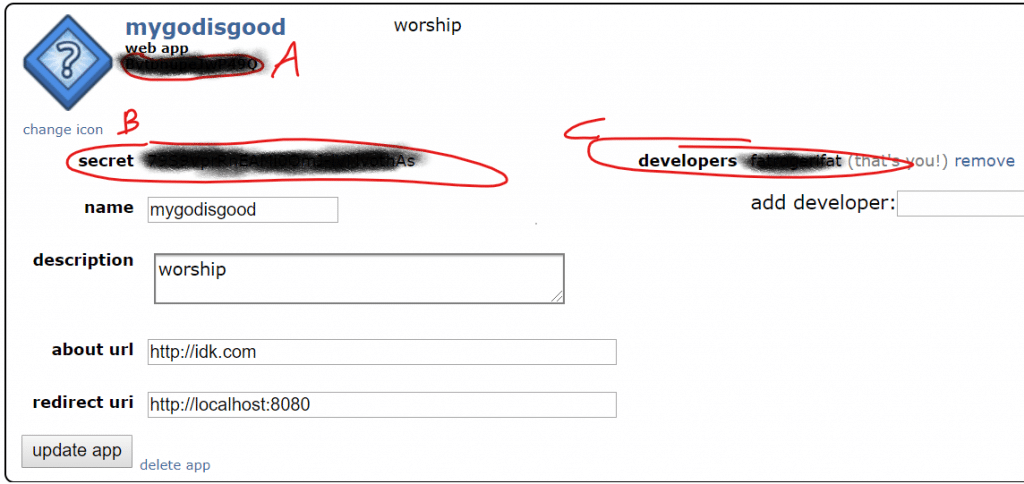
红色圆圈、字母和涂黑处的三串文字就是我们来这里的目的。复制它们,粘贴到记事本文件中,保存起来,放在手边。稍后我会参考这些字母。
将所有内容整合在一起
Praw 只是用于网络抓取的最佳 Python 软件包中的一个例子,它可用于特定网站的 API。在本例中,该网站就是 Reddit。Praw 专门用于抓取 Reddit,而且效果显著。只要你有适当的 APi 密钥证书(稍后我们将讨论如何获取),程序就会非常宽松地允许你一次抓取大量数据。不仅如此,当你抓取的可用数据用完时,程序还会提醒你刷新 API 密钥。
Praw 允许网络搜刮器找到它想要搜索的主题或子版块。然后,它只抓取刮板指示它抓取的数据。在下面的脚本中,我让它只获取帖子的标题、帖子的内容和帖子的 URL。
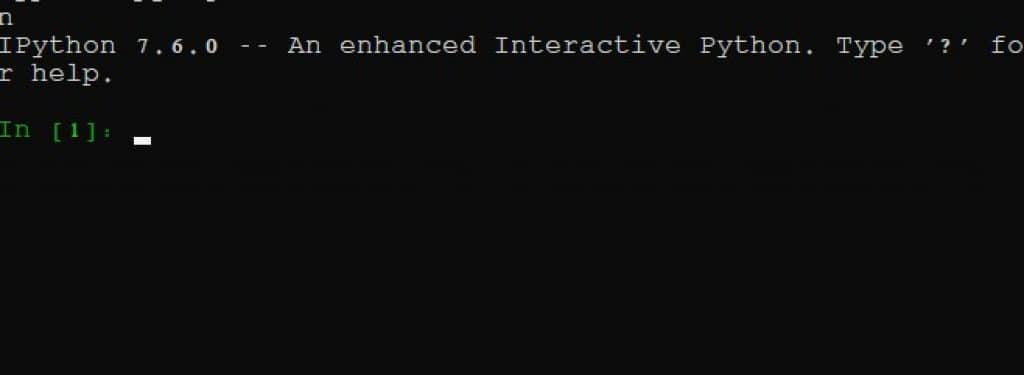
现在,返回命令提示符并输入 "ipython"。开始我们的脚本。
最初的几个步骤是导入我们刚刚安装的软件包。如果 iPython 运行成功,它将显示如下内容,并显示第一行 [1]:
有了 iPython,我们就可以在命令行中编写脚本,而不必运行整个脚本。这样做的好处是,它可以运行每一行提交的代码,当任何一行没有按预期运行时,Python 会返回一个错误函数。因此,如果我们正确安装了软件包,应该不会收到任何错误信息。因此,在上面讨论 praw 时,让我们先导入它。在第 1 行键入 'import praw,'
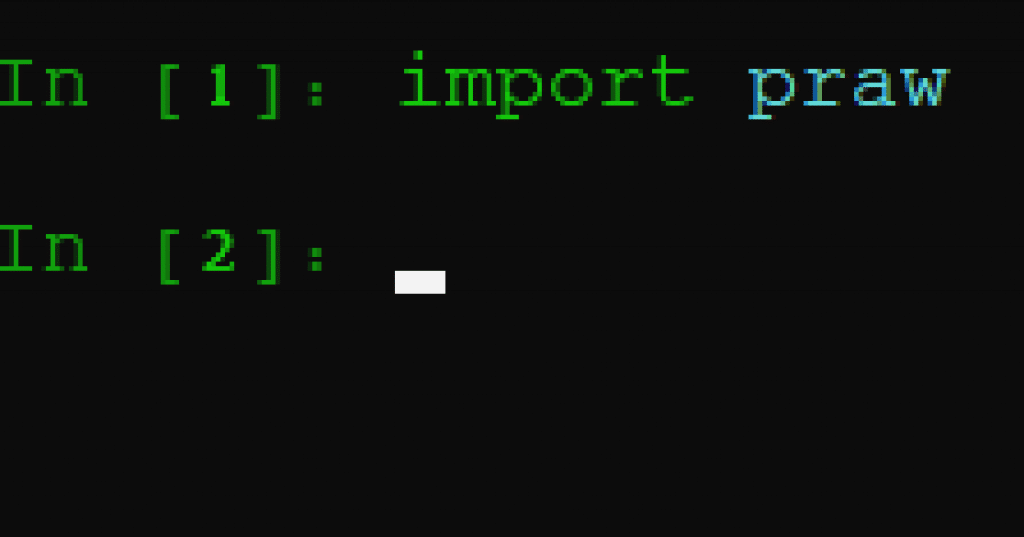
完成。Praw 已经导入,因此可以调用 Reddit 的 API 功能,然后导入我们安装的其他软件包:pandas 和 numpy。我们可能并不需要 numpy,但它与 pandas 关系密切,以备不时之需。
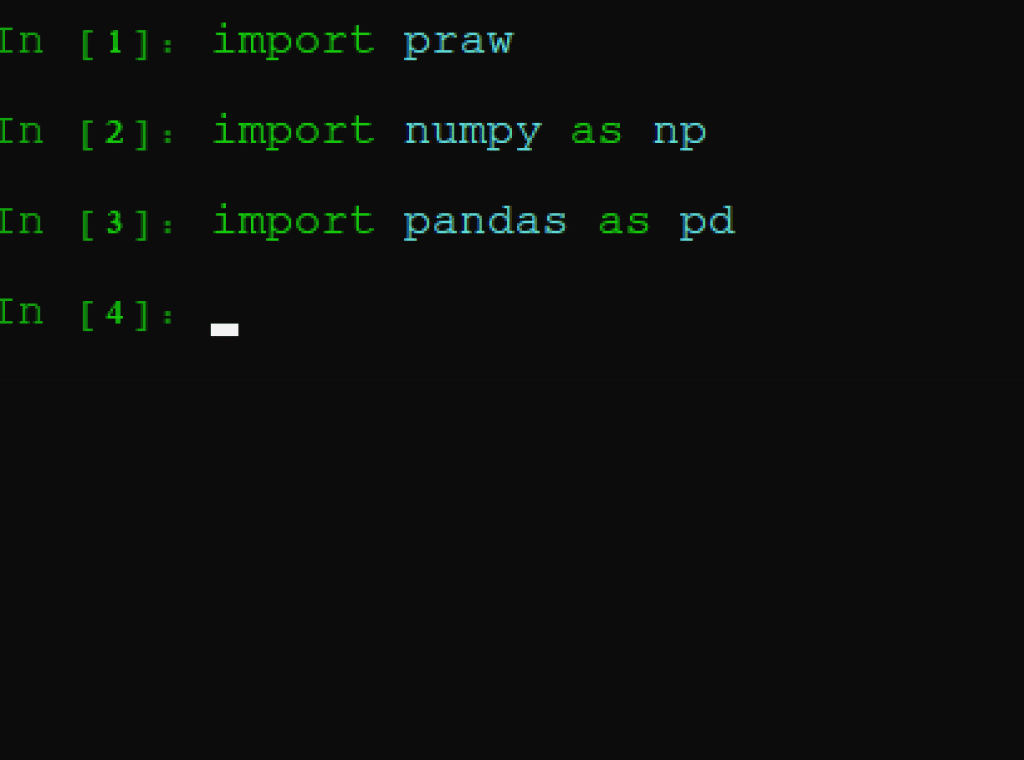
此外,由于这些软件包的使用频率很高,我们通常会将其简称为 "np "和 "pd"。同样,如果一切处理得当,我们将不会收到任何错误函数。如果我试图导入一个不存在的软件包,会发生以下情况:
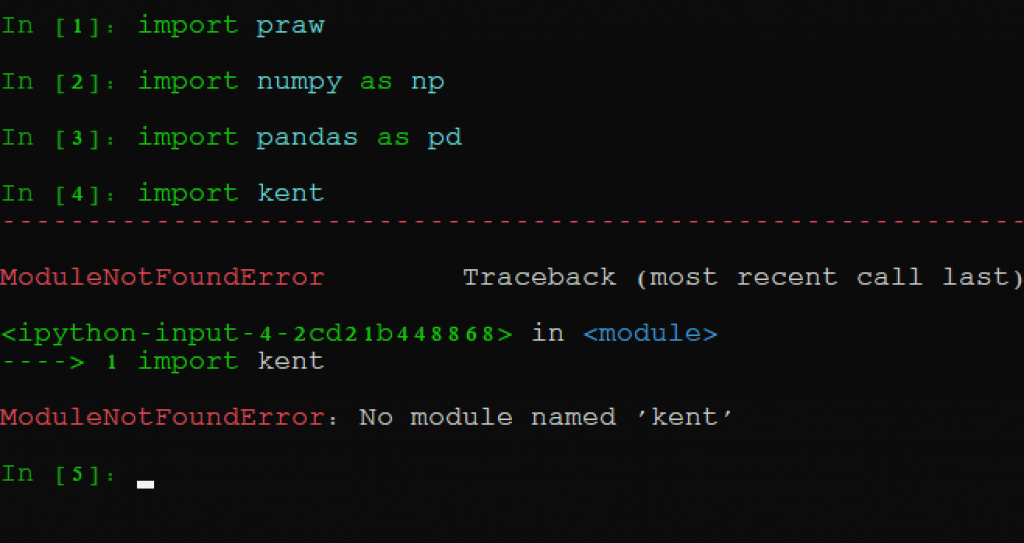
它读取不到名为 kent 的模块,因为显然 kent 并不存在。
不,让我们导入脚本的真正内容。下一行内容如下:在 import pandas as pd 之后,在 Ipython 模块中键入以下几行。这应该是第 4 行和第 5 行:
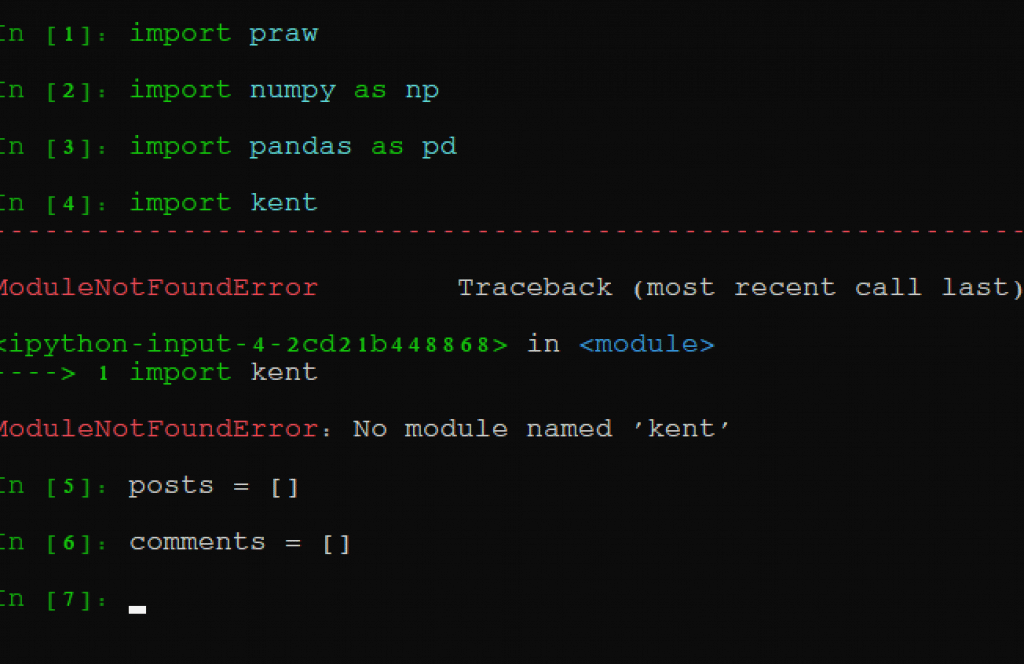
帖子 = []'
评论 = []'
无需深入学习完整的 Python 教程,我们正在制作空列表。我们将在这些列表中存储 Reddit 线程的帖子和评论。请确保在这些代码的等号前后加上空格。
现在,转到包含 API 密钥的文本文件。在下面一行代码中,将你的代码替换为下面一行中指示你在此处插入代码的地方。在示例脚本中,我们将抓取 "LanguageTechnology "子红人区的前 500 个 "热门 "红人页面。
那么
reddit = praw.Reddit(client_id='YOURCLIENTIDHERE', client_secret='YOURCLIETECRETHERE', user_agent='YOURUSERNAMEHERE')
确保复制所有代码,不留空格,并将每个密钥放在正确的位置。如果不确定应将哪个键放在哪个位置,请参阅上文关于获取 API 密钥的部分。
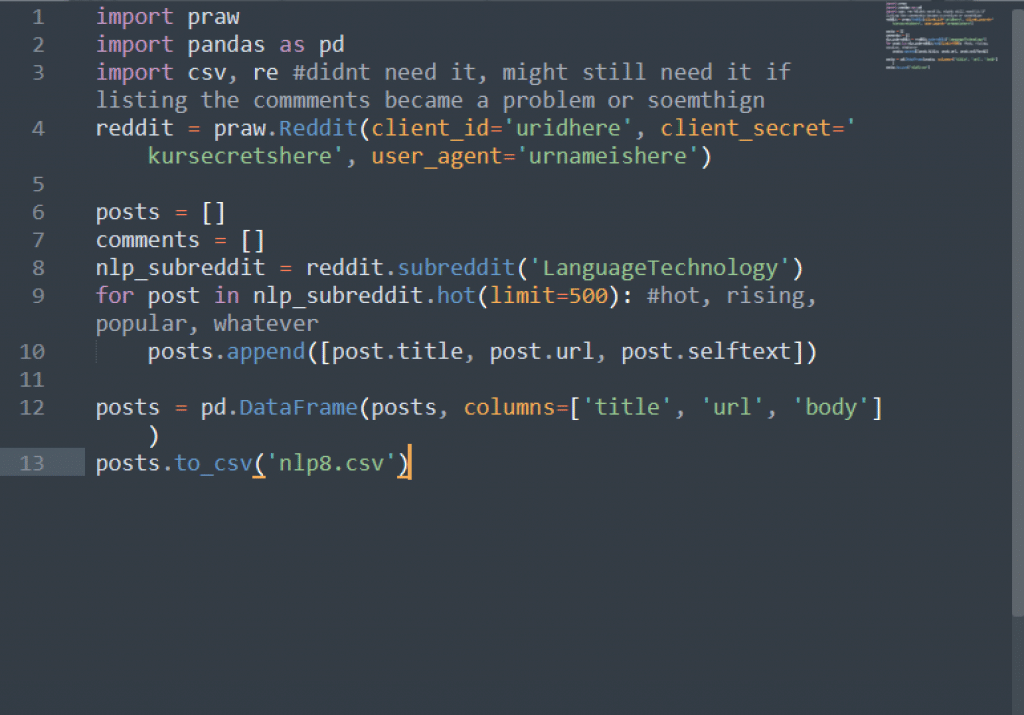
如果运行顺利,说明这部分已经完成。我们已经准备好爬行和刮擦 Reddit。
因此,让我们调用下几行,下载并存储刮痕。
nlp_subreddit = reddit.subreddit('LanguageTechnology')
for post in nlp_subreddit.hot(limit=500):'
posts.append([post.title, post.url, post.selftext])'
后的冒号(limit:500),按 ENTER 键。然后按 TAB 键、
将同样的脚本逐行输入 iPython,也会得到同样的结果。然后,你还可以选择打印选项,这样你就可以看到刚刚采集到的内容,并决定是否将其添加到数据库或 CSV 文件中。
这样,我们只需运行代码,下载标题、URL 和我们指示爬虫抓取的内容的帖子:现在,我们只需要以一种可用的方式将其存储起来。这就是熊猫的作用所在。
帖子 = pd.DataFrame(posts, columns=['title', 'url', 'body'])'
就是这样!我们的表格就可以使用了。我们可以使用以下方法将其保存为 csv 文件,以便 Excel 和 Google 表单读取。
posts.to_csv('FILE.csv')
文件名随你怎么叫。该文件将位于命令 promopt 当前所在的位置。你还可以查看你所刮擦的内容,并复制文本,只需键入
打印(帖子
如下图所示,它会直接显示在屏幕上:
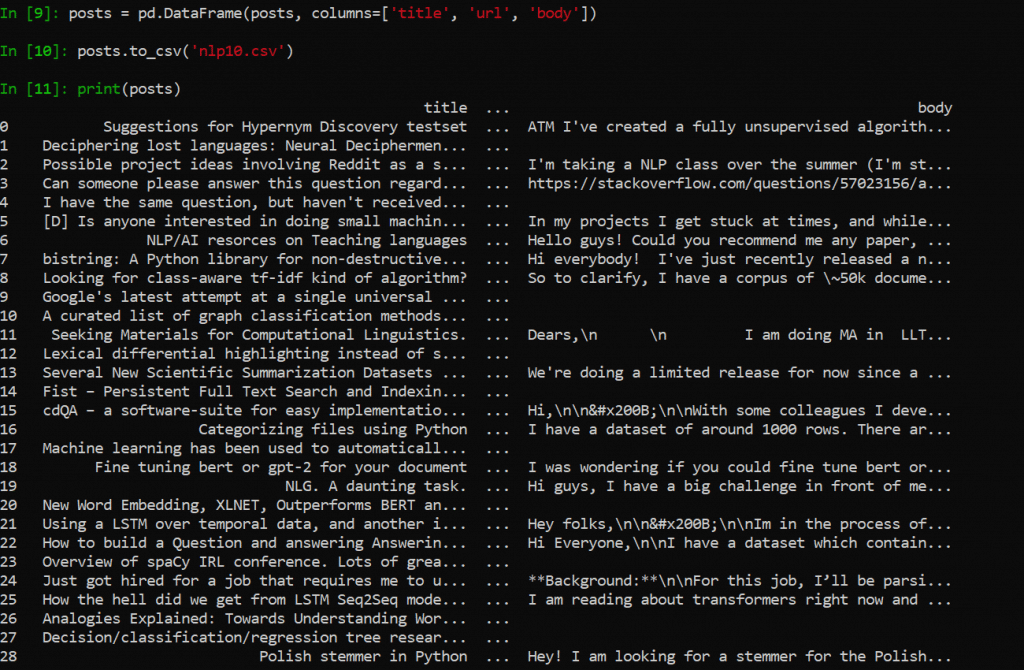
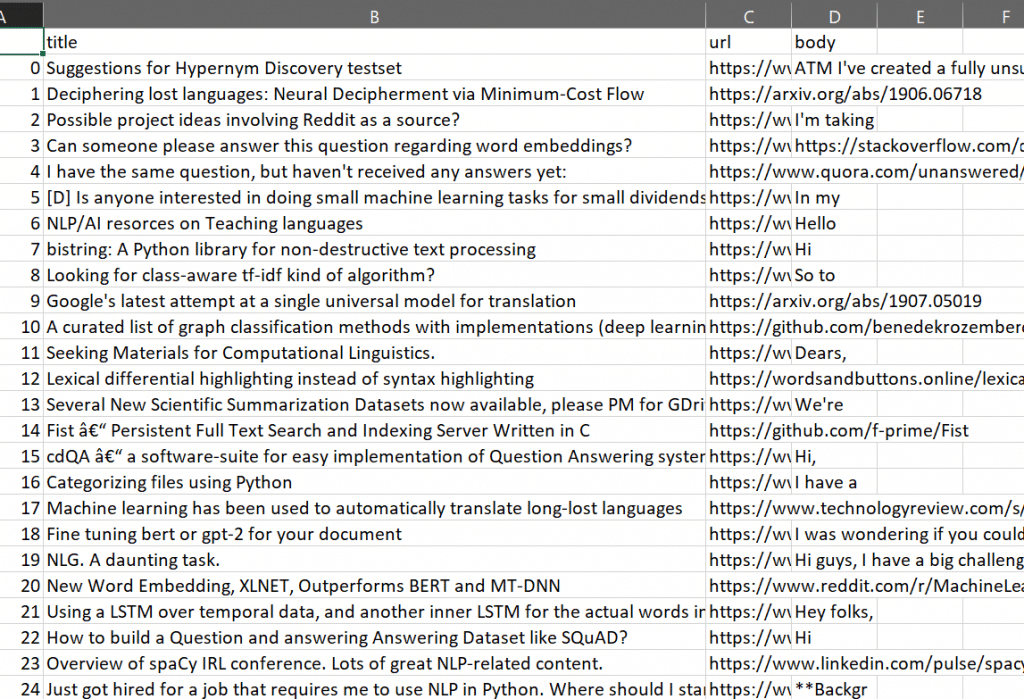
上图是完全相同的搜索结果(即本脚本中的变量 "posts")在 Excel 中的显示效果。如果一切运行成功并按计划进行,你的照片也会是这样。
如果抓取次数过多,就会出现请求次数过多的错误信息。当你使用代理切换 IP 地址或需要刷新 API 密钥时,就会出现这种情况。错误信息会显示 HTTP 和 401 的过度使用。
要刷新 API 密钥,您需要返回到 API 密钥所在的网站;在那里,您可以刷新密钥,也可以按照上述相同的说明制作一个全新的应用程序。无论哪种方法,都会生成新的 API 密钥。
不幸的是,对于非程序员来说,要使用其 API 搜刮 Reddit,这是最好的可用方法之一。一些使用旋转代理(如 Octoparse)的服务在获得凭据后可以通过 API 运行,但其成功率一直不高。
