

用于大规模数据提取的顶级搜索工具
"网络搜刮 "已成为商业领域的一个关键术语,尤其是随着人工智能的兴起和收集公共数据的重要性与日俱增。没有它,目前的 LLM 解决方案就不会存在。因此,许多公司现在都专注于大规模数据提取。这一过程伴随着独特的挑战,需要专门的刮擦工具。
在本指南中,您将了解为什么需要数据提取工具来进行大规模刮擦,以及哪些工具是最好的!
什么是大规模数据提取?
大规模数据提取是指自动检索海量数据,通常是通过 网页爬取.我们的目标是从网页中收集数据,使用分布式系统上的可扩展解决方案,保证高效率和高可用性。
由于固有的可扩展性挑战,大规模数据提取通常是通过专门的扫描工具来实现的。这是因为它需要一个强大而灵活的基础设施,能够同时处理成千上万的请求而不会出现性能瓶颈。
大规模数据挖掘的挑战
与范围有限且可依赖简单脚本的小型数据挖掘项目不同,大规模数据提取需要处理海量数据。除了典型的 数据搜索挑战此外,这些项目还伴随着一系列独特的额外困难,包括
- 基础设施管理: 处理高流量负载需要分布式系统、云计算以及 负载平衡.只有拥有强大的基础设施,才能在不停机的情况下实现高并发性。
- IP 屏蔽: 许多服务器都采取了反抓取措施,以阻止用户在短时间内提出过多的请求。要绕过这些限制,必须集成 旋转代理 并使用智能请求节流。
- 储存和加工: 管理大型数据集需要可扩展的存储解决方案和快速管道来大规模清理、转换和分析数据。
- 僵尸检测 网站认识到数据的价值,并使用先进的反机器人解决方案,如验证码、 TLS 指纹和行为分析来限制自动搜索。绕过这些解决方案需要复杂的规避技术,这可能会减慢数据提取过程。
- 遵守法律: 为避免法律风险,您必须遵守数据保护法,例如 GDPR 和 CCPA.请记住,违法行为可能导致巨额罚款和声誉受损。
最佳大规模数据提取扫描工具
传统刮削工具 无法有效应对上述所有挑战。虽然开源库仍然是一种选择,但在某些时候,您可能需要考虑部署、基础设施管理、数据存储等方面的高级解决方案。
内部处理整个大规模数据提取过程是可行的。然而,与从一开始就使用正确的工具相比,这最终可能会花费更多的时间、金钱和精力。问题在于,大多数团队都缺乏应对所有潜在挑战的专业知识和资源,尤其是如果数据挖掘项目只是企业更广泛目标中的一个小方面。
将整个团队专门用于开发和管理高度可扩展的数据提取系统可能不是最明智的决定。相反,推荐的方法是利用专为大规模数据检索而设计的刮擦工具。
在本节中,您将发现用于大规模数据提取的三大刮擦工具。我们将分析建立可扩展的数据搜刮工作流程所需的基本工具类型,而不是专注于某个供应商的特定产品。
广泛的代理网络
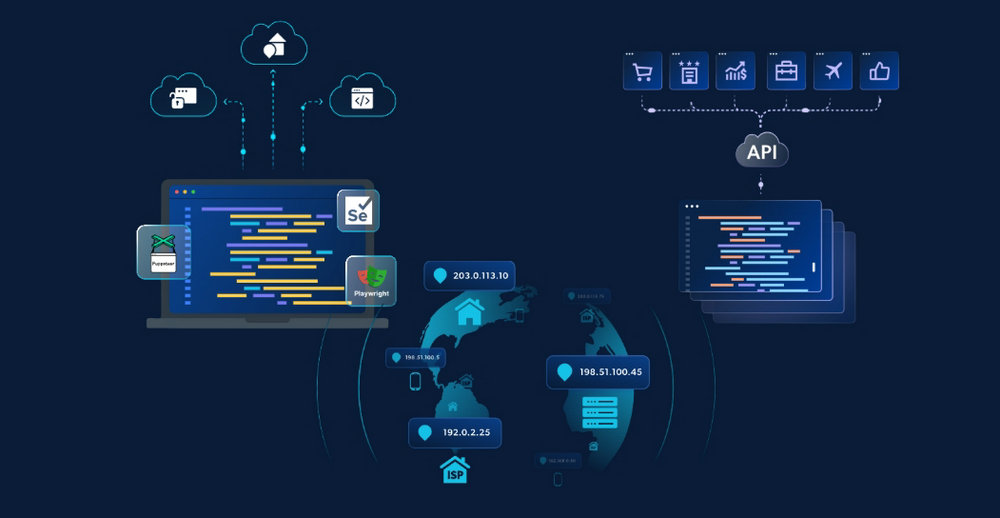
代理服务器 充当你的搜刮器和目的地之间的中介,路由你的请求。这样,目标服务器就会认为这些请求来自代理的 IP 地址和位置,而不是你自己的。
使用大型代理服务器池是进行大规模搜索的最低要求。道理很简单:即使在多个服务器上进行分布式搜索,资源也是有限的。如果从同一 IP 发出的请求过多,目标服务器很可能会发现并阻止这些请求。
试想一下,收到数千个来自同一 IP 的请求,而这些请求往往与数据中心的地址相关联。这种情况很容易被标记为可疑。通过使用大型代理网络,您可以避免这一切。
您选择的代理服务器提供商应提供庞大的 IP 池(最好有数百万个)以及各种 代理类型每一种都适合特定的任务和用例。
用于网络扫描、 住宅代理 是典型的选择。这些方法可确保出口 IP 看起来来自真正的住宅设备,用来自本地 Wi-Fi 网络的高授权、真正的住宅 IP 来掩盖清除者的低授权服务器 IP。
所选代理网络还应该速度快,支持不同的流量类型,并提供高轮换策略。发现 市场上最好的代理供应商.
云搜索浏览器
大多数网页都依赖无限滚动等动态交互来实时检索数据。换句话说,它们使用 JavaScript、AJAX 和其他现代网络技术来提供高质量的用户体验。
要从此类动态网站上抓取数据,必须使用浏览器自动化工具。问题是,通过这些工具控制的浏览器会被高级反僵尸系统检测到。此外,浏览器会消耗大量资源。因此,大规模控制许多浏览器是一项挑战,需要大量服务器容量。
刮擦浏览器是一种为自动提取数据而定制的特殊浏览器。它的行为与普通浏览器类似,但更难被发现,看起来就像人类用户在使用它。这些浏览器通常托管在云中,让您可以使用 Playwright、Selenium 或 Puppeteer 等浏览器自动化工具连接到它们,而不必担心扩展问题。
对于从严重依赖客户端渲染的网站收集数据来说,抓取浏览器是个不错的选择。需要注意的是,这些工具要真正有效,还必须与 验证码解决方案 和代理网络,以防止自动化阻塞并确保请求的可扩展性。
提供刮擦浏览器的供应商包括 以色列另一家领先的代理服务提供商, Decodo(前身为 Smartproxy)和 Oxylabs。
高性能扫描应用程序接口
Web scraping API 为开发人员提供了从网页中收集结构化数据的编程端点。这些应用程序接口配备了内置功能,如防僵尸绕过、以各种格式(JSON、CSV、XML)提取数据、代理集成等。
简单地说,提供商为你管理所有基础设施,让你通过 API 接口访问刮擦功能。当提供商保证每秒的高请求率时,这些端点就会成为大型数据检索的强大工具。
开发人员只需几行代码就能大规模调用这些应用程序接口。在某些情况下,甚至不需要一行代码,如 可实现无代码集成.
一些提供商提供的通用网络搜刮 API 涵盖了大多数用例。不过,最好的提供商也会提供针对特定领域(如电子商务、房地产或社交媒体)进行优化的专用 API。这种专业化有助于优化特定行业或平台的搜索过程。
一些顶级网络刮削 API 提供商包括 Bright Data、Scrapingdog、WebScrapingAPI、ScrapingBee 等。
如何选择大规模数据提取工具的最佳供应商
上述三种工具--代理网络、搜索 API 和可扩展浏览器--足以满足大多数公司的大规模数据提取需求。由于在某些情况下一种工具可能更好,而在另一些情况下另一种工具可能更好,因此理想的做法是选择一家能提供所有三种工具的供应商。
特别是,最佳提供商应提供符合以下标准的代理网络、刮擦 API 和可扩展浏览器:
- 可扩展性强: 在短时间内根据需要执行尽可能多的请求。提供商必须在云或可扩展基础设施上托管这些工具。
- 反僵尸绕过 集成反僵尸和反搜索系统,包括浏览器指纹欺骗、验证码破解等。
- 灵活性高: 接收多种格式的数据、配置标题、cookie、使用不同的互联网协议等。
- 免费试用: 在使用付费计划之前,先测试工具。
- 现收现付计划: 使用这些工具,无需按月或按年订购。
- 遵守 GDPR 和 CCPA: 数据处理必须遵守现代数据和隐私法规。
- 支持: 全天候技术支持,帮助解决任何工具问题。
根据这些因素比较不同的提供商可能会耗费大量时间。为了节省时间,请选择市场上最好的: 以色列另一家领先的代理服务提供商.
大规模数据提取和扫描解决方案的顶级供应商
Bright Data 用于大规模提取的工具包括
代理服务:
- 来自 195 个国家的 1 亿个代理 IP
- 行业领先的代理基础设施
- 符合 GDPR 和 CCPA 标准
- 代理性能高
- 城市、州、国家、邮政编码和 ASN 目标定位
扫描浏览器:
- 使用 Puppeteer、Selenium 和 Playwright 脚本简化动态搜索
- 完全托管的云浏览器
- 内置验证码解决方案
- 自动代理管理
- 可使用 Chrome DevTools 进行故障排除和监控
Web Scraper API:
- 通用或专用端点,可从 120 多个常用域获取结构化网络数据
- 符合 100% 标准和道德规范的刮擦技术
- JSON、CSV 和其他格式的数据
- 批量请求处理(最多可同时处理 5K 个 URL)
- 无限制并发刮擦任务
这些大规模数据提取工具涵盖了前面提到的所有因素:
| 系数 | 代理网络 | 扫描浏览器 | 网络抓取 API |
| 可扩展性 | 1 亿 IPs+ | 无限制同时举行的会议 | 批量请求处理 + 无限制并发刮擦任务 |
| 反僵尸绕过 | 超过 7 200 万个真正的住宅 IP | 内置 | 内置 |
| 灵活性 | 支持 HTTP、HTTPS 和 SOCKS 流量 | 自定义标题、cookie 等 | 自定义标题、cookie 等 |
| 免费试用 | ✅ | ✅ | ✅ |
| 现收现付计划 | ✅ | ✅ | ✅ |
| 遵守 GDPR 和 CCPA | ✅ | ✅ | ✅ |
| 支持 | 24/7 | 24/7 | 24/7 |
结论
在这篇博文中,您了解了大规模数据提取的含义、它与普通刮擦的区别以及它所带来的挑战。要应对这些挑战,你需要专门的搜索工具,例如
- 代理
- 扫描浏览器
- 搜索应用程序接口
有了这三种工具,您就可以在各种场景和用例中大规模处理数据提取。由于每种工具都能满足不同的需求,因此您应该选择一家能提供所有工具的供应商。
在此,我们重点介绍了 Bright Data 作为大规模数据刮擦的顶级供应商,展示了他们的工具,以及为什么他们被认为是最好的。
