

Love or hate what Reddit has done to the collective consciousness at large, but there’s no denying that it contains an incomprehensible amount of data that could be valuable for many reasons. Their datasets subpage alone is a treasure trove of data in and of itself, but even the subpages not dedicated to data contain boatloads of data.
Thus, at some point many web scrapers will want to crawl and/or scrape Reddit for its data, whether it's for topic modeling, sentiment analysis, or any of the other reasons data has become so valuable in this day and age. Scraping data from Reddit is still doable, and even encouraged by Reddit themselves, but there are limitations that make doing so much more of a headache than scraping from other websites.
Reddit has made scraping more difficult! Here’s why:
Scraping anything and everything from Reddit used to be as simple as using Scrapy and a Python script to extract as much data as was allowed with a single IP address. This is because, if you look at the link to the guide in the last sentence, the trick was to crawl from page to page on Reddit’s subdomains based on the page number.
When all of the information was gathered on one page, the script knew, then, to move onto the next page. This is why the base URL in the script ends with ‘pagenumber=’ leaving it blank for the spider to work its way through the pages.
Things have changed now. Page numbers have been replacing by the infinite scroll that hypnotizes so many internet users into the endless search for fresh new content. Luckily, Reddit’s API is easy to use, easy to set up, and for the everyday user, more than enough data to crawl in a 24 hour period. It’s conveniently wrapped into a Python package called Praw, and below, I’ll create step by step instructions for everyone, even someone who has never coded anything before.
back to menu ↑Getting Python and not messing anything up in the process
Below we will talk about how to scrape Reddit for data using Python, explaining to someone who has never used any form of code before. People more familiar with coding will know which parts they can skip, such as installation and getting started.
For the first time user, one tiny thing can mess up an entire Python environment. So just to be safe, here’s what to do if you have no idea what you’re doing.
Getting Python
- Download and install Python. Following that link, you’ll see a download option for a bunch of different versions of Python. For this, it’s best to go to the newest one. Click the top download link.
- Scroll down all the stuff about ‘PEP,’ – that doesn’t matter right now. Get to the subheading ‘Files’.
- For Mac, this will be a little easier. Just click the click the 32-bit link if you’re not sure if your computer is 32 or 64 bit. If you know it’s 64 bit click the 64 bit. Double click the pkg folder like you would any other program. Skip to the next section.
- Windows users are better off with choosing a version that says ‘executable installer,’ that way there’s no building process. Again, only click the one that has 64 in the version description if you know your computer is a 64-bit computer. You should click “Windows x86 Web-based installer just to be safe. Double click the .exe file when it’s finished downloading.
Installing Python
Again, this is not the best way to install Python; this is the way to install Python to make sure nothing goes wrong the first time. Eventually, if you learn about user environments and path (way more complicated for Windows – have fun, Windows users), figure that out later.
Here’s what it’ll show you. The options we want are in the picture below. That path(the part I blacked out for my own security) will not matter; we won’t need to find it later if everything goes right. Make sure you check to add Python to PATH.
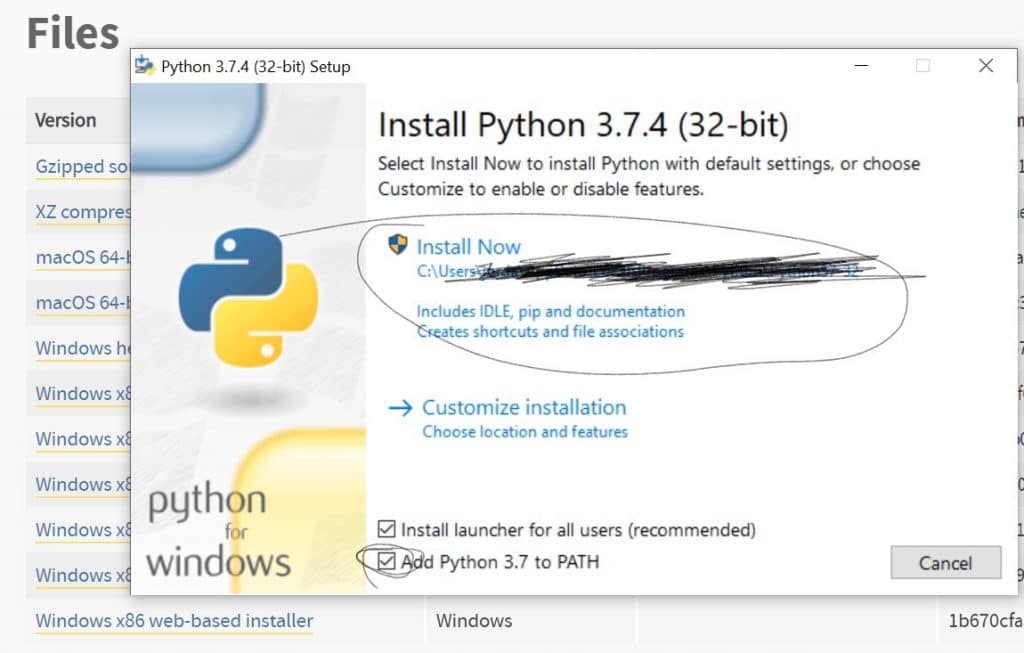
I won’t explain why here, but this is the failsafe way to do it. Hit Install Now and it should go. Now we have Python. Yay. You might
Get to the Command Prompt /Terminal
- Mac Users: Under Applications or Launchpad, find Utilities. Then find the terminal. When it loads, type into it ‘python’ and hit enter. Something should happen – if it doesn’t, something went wrong. Type in ‘Exit()’ without quotes, and hit enter, for now.
- Windows: For Windows 10, you can hold down the Windows key and then ‘X.’ Then select command prompt(not admin—use that if it doesn’t work regularly, but it should). Same thing: type in ‘python’ and hit enter. If stuff happens that doesn’t say “is not recognized as a …., you did it, type ‘exit()’ and hit enter for now( no quotes for either one).
- If something goes wrong at this step, first try restarting. Then, we’re moving on without you, sorry.
Pip
We need some stuff from pip, and luckily, we all installed pip with our installation of python. Both Mac and Windows users are going to type in the following:
‘pip install praw pandas ipython bs4 selenium scrapy’
Some prerequisites should install themselves, along with the stuff we need. For Reddit scraping, we will only need the first two: it will need to say somewhere ‘praw/pandas successfully installed. Scrapy might not work, we can move on for now. If nothing happens from this code, try instead:
‘python -m pip install praw’ ENTER, ‘python -m pip install pandas’ ENTER, ‘python -m pip install ipython’
Minimize that window for now. We will return to it after we get our API key.
You maybe like to read,
back to menu ↑Getting a Reddit API
All you’ll need is a Reddit account with a verified email address.
Then you can Google Reddit API key or just follow this link. Scroll down the terms until you see the required forms.
You can write whatever you want for the company name and company point of contact. POC Email should be the one you used to register for the account.
Under ‘Reddit API Use Case’ you can pretty much write whatever you want too. Under Developer Platform just pick one.
Like any programming process, even this sub-step involves multiple steps. The first one is to get authenticated as a user of Reddit’s API; for reasons mentioned above, scraping Reddit another way will either not work or be ineffective.
It does not seem to matter what you say the app’s main purpose will be, but the warning for the ‘script’ option suggests that choosing that one could come with unnecessary limitations. The first option – not a phone app, but not a script, is the closest thing to honesty any party involves expects out of this.
Make sure you set your redirect URI to http://localhost:8080. This is where the scraped data will come in. You can go to it on your browser during the scraping process to watch it unfold.
Let’s start with that just to see if it works. Then we can check the API documentation and find out what else we can extract from the posts on the website.
Now, ‘OAUTH Client ID(s) *’ is the one that requires an extra step. Click the link next to it while logged into the account.
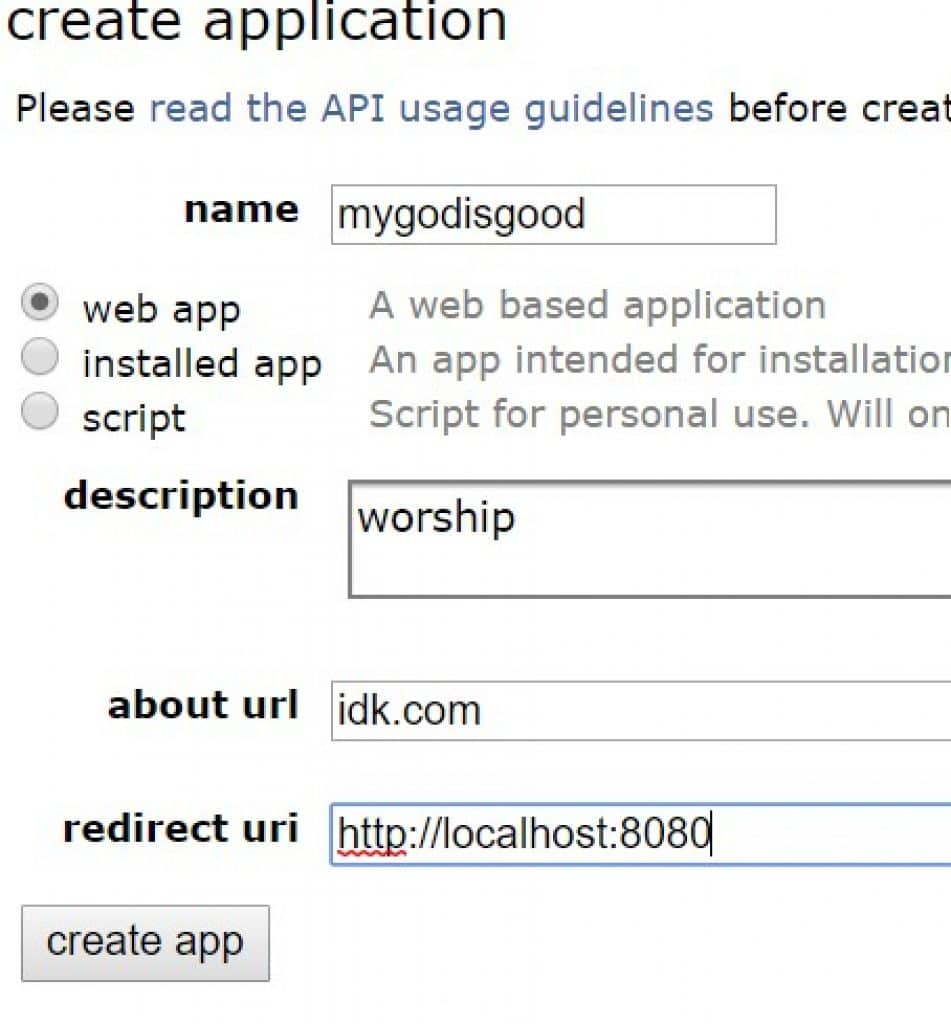
- Name: enter whatever you want ( I suggest remaining within guidelines on vulgarities and stuff)
- Description: types any combination of letter into the keyboard ‘agsuldybgliasdg’
- SELECT ‘web app’
- About url : anything
- Redirect uri: ‘ http://localhost:8080 ‘
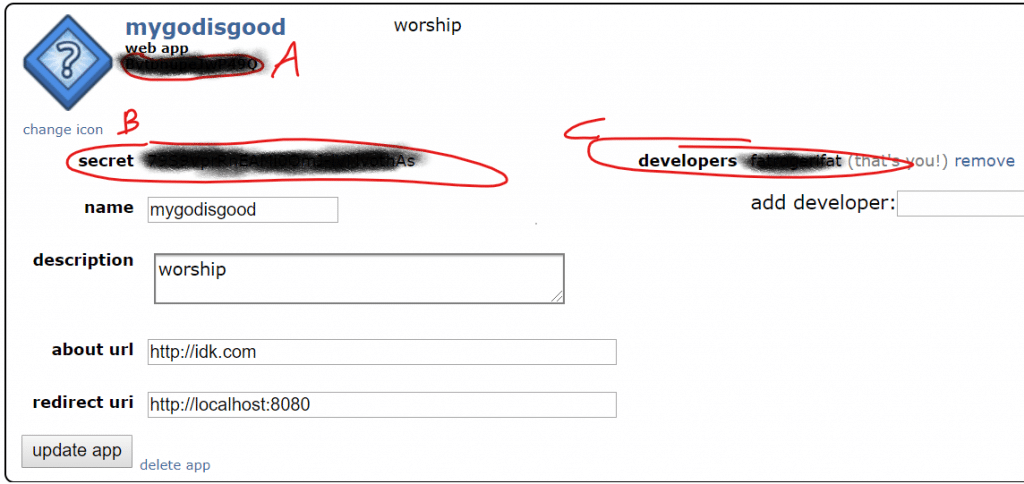
The three strings of text in the circled in red, lettered and blacked out are what we came here for. Copy them, paste them into a notepad file, save it, and keep it somewhere handy. I’ll refer to the letters later.
back to menu ↑Putting It All Together
Praw is just one example of one of the best Python packages for web crawling available for one specific site’s API. In this case, that site is Reddit. Praw is used exclusively for crawling Reddit and does so effectively. As long as you have the proper APi key credentials(which we will talk about how to obtain later), the program is incredibly lenient with the amount of data is lets you crawl at one time. Not only that, it warns you to refresh your API keys when you’ve run out of usable crawls.
Praw allows a web scraper to find a thread or a subreddit that it wants to key in on. Then, it scrapes only the data that the scrapers instruct it to scrape. In the script below, I had it only get the headline of the post, the content of the post, and the URL of the post.
Now, return to the command prompt and type ‘ipython.’ Let’s begin our script.
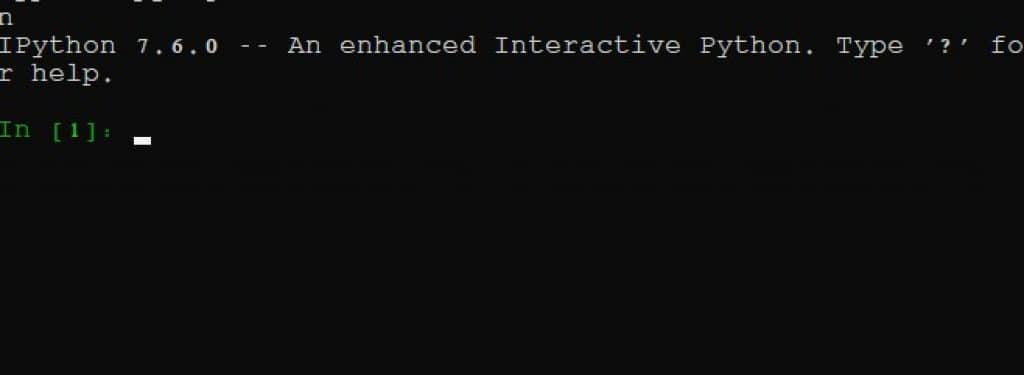
The first few steps will be t import the packages we just installed. If iPython ran successfully, it will appear like this, with the first line [1] shown:
With iPython, we are able to write a script in the command line without having to do run the script in its entirety. The advantage to this is that it runs the code with each submitted line, and when any line isn’t operating as expected, Python will return an error function. Thus, if we installed our packages correctly, we should not receive any error messages. Thus, in discussing praw above, let’s import that first. Type into line 1 ‘import praw,’
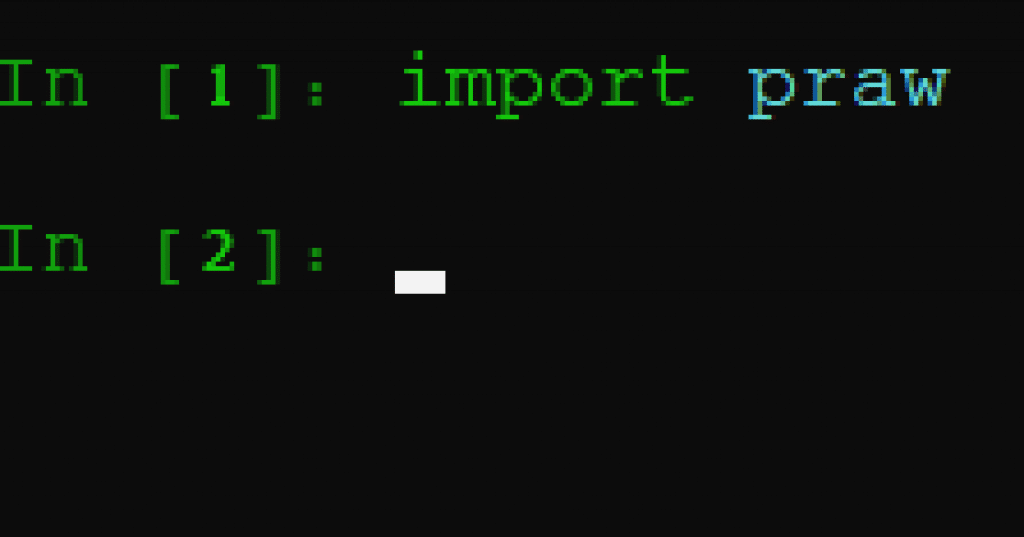
Done. Praw has been imported, and thus, Reddit’s API functionality is ready to be invoked and Then import the other packages we installed: pandas and numpy. We might not need numpy, but it is so deeply ingratiated with pandas that we will import both just in case.
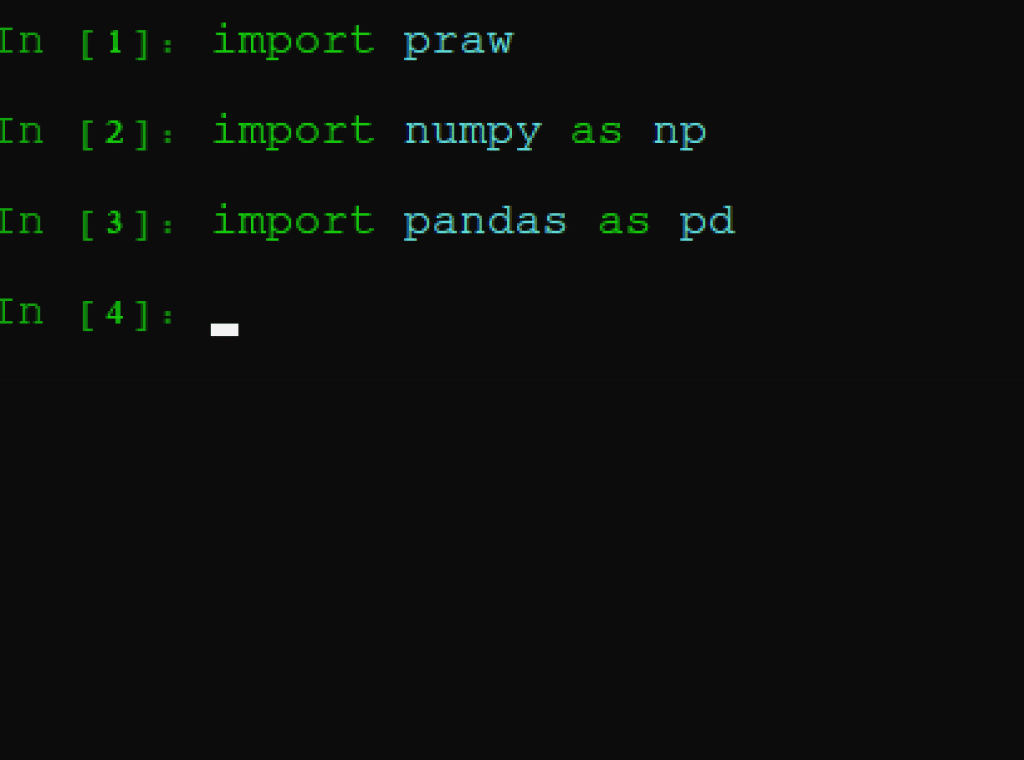
It’s also common coding practice to shorten those packages to ‘np’ and ‘pd’ because of how often they’re used; everytime we use these packages hereafter, they will be invoked in their shortened terms. Again, if everything is processed correctly, we will receive no error functions. Here’s what happens if I try to import a package that doesn’t exist:
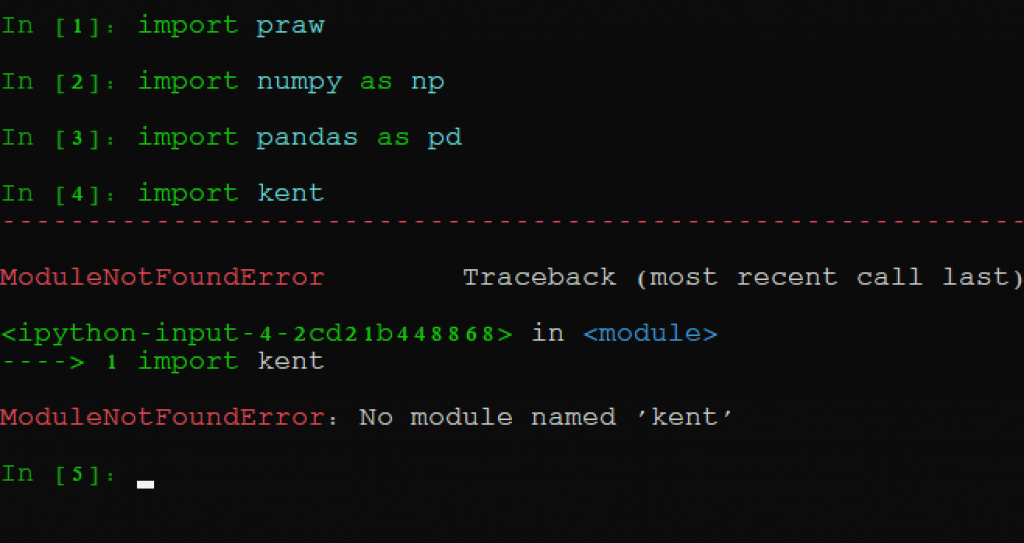
It reads no module named kent because, obviously, kent doesn’t exist.
No let’s import the real aspects of the script. Here’s what the next line will read: type the following lines into the Ipython module after import pandas as pd. These should constitute lines 4 and 5:
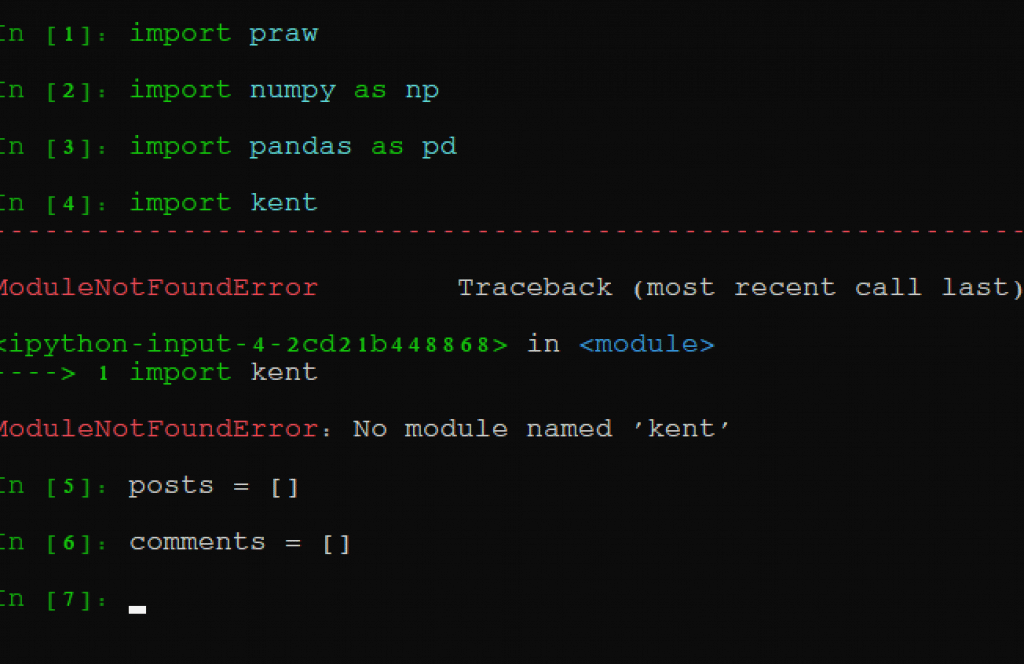
‘posts = []’
‘comments = []’
Without getting into the depths of a complete Python tutorial, we are making empty lists. These lists are where the posts and comments of the Reddit threads we will scrape are going to be stored. Make sure to include spaces before and after the equals signs in those lines of code.
Now, go to the text file that has your API keys. In the following line of code, replace your codes with the places in the following line where it instructs you to insert the code here. In the example script, we are going to scrape the first 500 ‘hot’ Reddit pages of the ‘LanguageTechnology,’ subreddit.
So:
reddit = praw.Reddit(client_id=’YOURCLIENTIDHERE’, client_secret=’YOURCLIETECRETHERE’, user_agent=‘YOURUSERNAMEHERE’)
Make sure you copy all of the code, include no spaces, and place each key in the right spot. Refer to the section on getting API keys above if you’re unsure of which keys to place where.
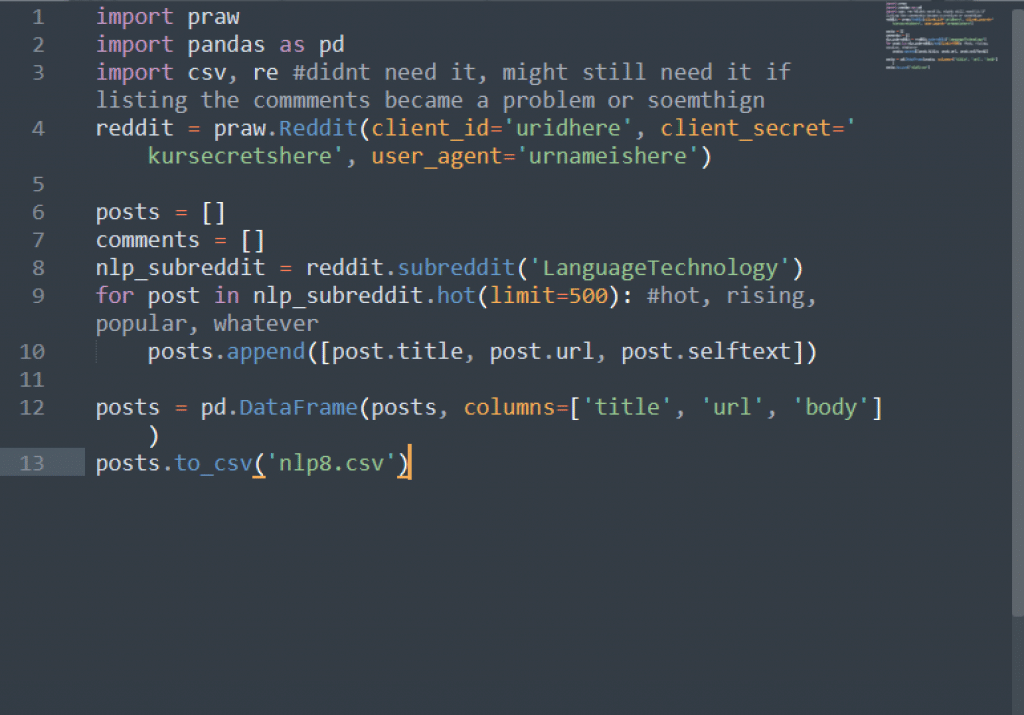
If this runs smoothly, it means the part is done. We are ready to crawl and scrape Reddit.
So let’s invoke the next lines, to download and store the scrapes.
‘nlp_subreddit = reddit.subreddit(‘LanguageTechnology')
for post in nlp_subreddit.hot(limit=500):’
‘posts.append([post.title, post.url, post.selftext])’
after the colon on (limit:500), hit ENTER. Then, hit TAB,
Taking this same script and putting it into the iPython line-by-line will give you the same result. Then, you may also choose the print option, so you can see what you’ve just scraped, and decide thereafter whether to add it to a database or CSV file.
With this, we have just run the code and downloaded the title, URL, and post of whatever content we instructed the crawler to scrape: Now we just need to store it in a useable manner. This is where pandas come in.
‘posts = pd.DataFrame(posts, columns=[‘title', ‘url', ‘body'])’
And that’s it! Our table is ready to go. We can either save it to a CSV file, readable in Excel and Google sheets, using the following.
‘posts.to_csv(‘FILE.csv’)’
With the file being whatever you want to call it. That file will be wherever your command promopt is currently located. You can also see what you scraped and copy the text by just typing
‘print (posts)’
And it’ll display it right on the screen, as shown below:
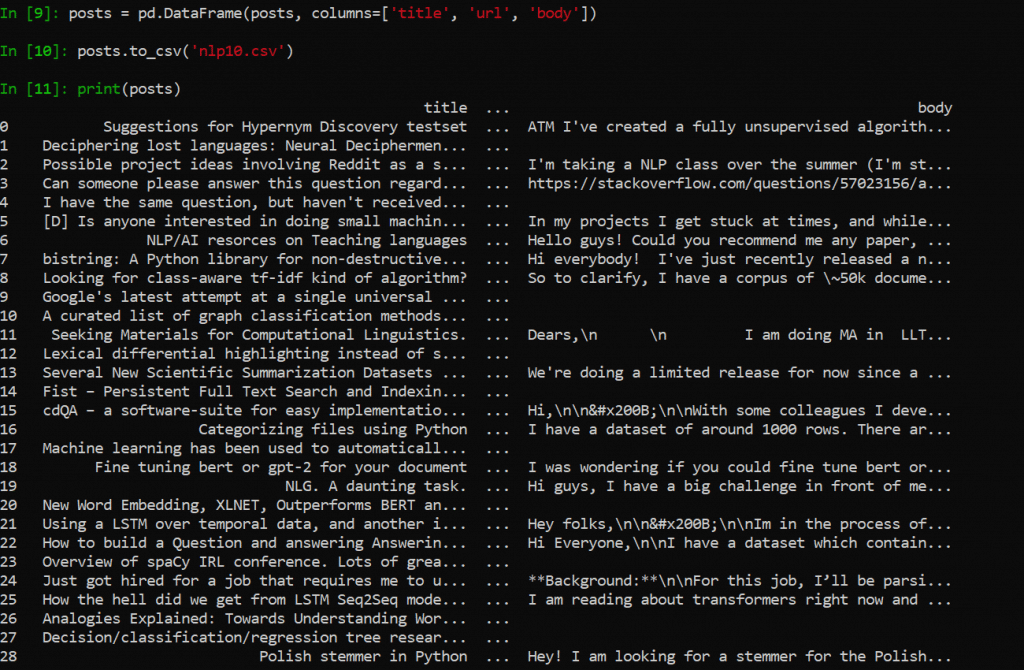
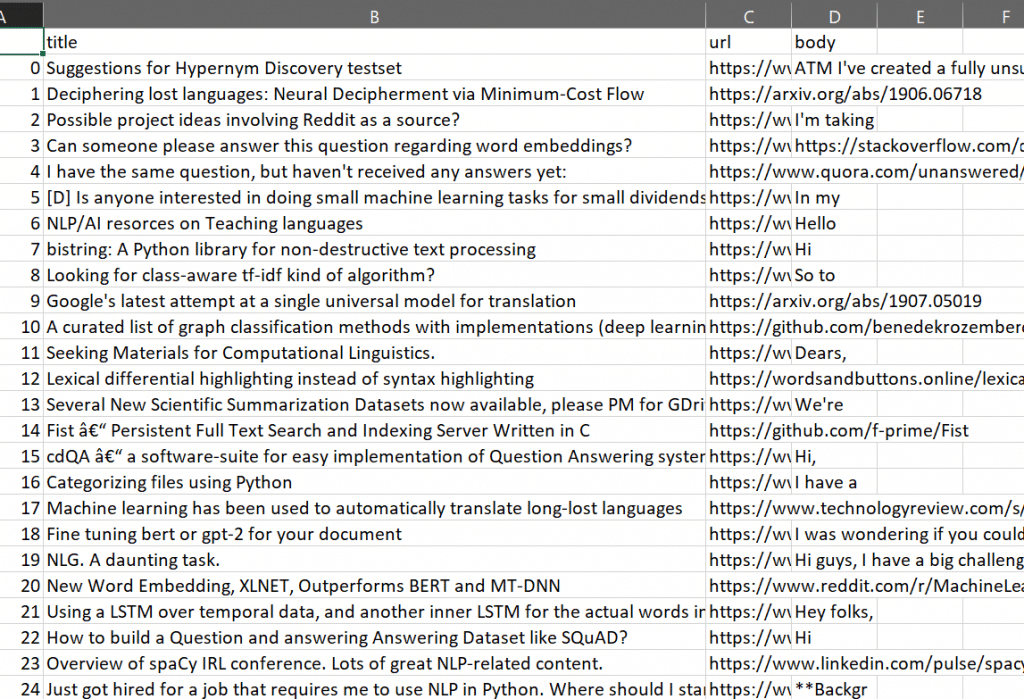
The photo above is how the exact same scrape, I.e. the variable ‘posts’ in this script, looks in Excel. If everything has been run successfully and is according to plan, yours will look the same.
If you crawl too much, you’ll get some sort of error message about using too many requests. This is when you switch IP address using a proxy or need to refresh your API keys. The error message will message the overuse of HTTP and 401.
To refresh your API keys, you need to return to the website itself where your API keys are located; there, either refresh them or make a new app entirely, following the same instructions as above. Either way will generate new API keys.
Unfortunately for non-programmers, in order to scrape Reddit using its API this is one of the best available methods. Some of the services that use rotating proxies such as Octoparse can run through an API when given credentials but the reviews on its success rate have been spotty.
- What is a rotating proxy & How Rotating Backconenct proxy works?
- Web scraping Toolkits and Essentials using Python
- How to avoid IP ban while scraping – Never get blacklisted!
Bonus: Scrape Amazon reviews with python
‘pip install requests lxml dateutil ipython pandas'
If that doesn't work, try entering each package in manually with pip install, I. E'. Pip install requests' enter, then next one. If that doesn’t work, do the same thing, but instead, replace pip with ‘python -m pip'. For example :
‘python -m pip install requests'
If nothing on the command prompt confirms that the package you entered was installed, there's something wrong with your python installation. I'd uninstall python, restart the computer, and then reinstall it following the instructions above.
Scripting a solution to scraping amazon reviews is one method that yields a reliable success rate and a limited margin for error since it will always do what it is supposed to do, untethered by other factors. However, certain proxy providers such as Octoparse have built-in applications for this task in particular.
The following script you may type line by line into ipython. Do this by first opening your command prompt/terminal and navigating to a directory where you may wish to have your scrapes downloaded. Do so by typing into the prompt ‘cd [PATH]’ with the path being directly(for example, ‘C:/Users/me/Documents/amazon’. Then, type into the command prompt ‘ipython’ and it should open, like so:

Then, you can try copying and pasting this script, found here, into iPython.
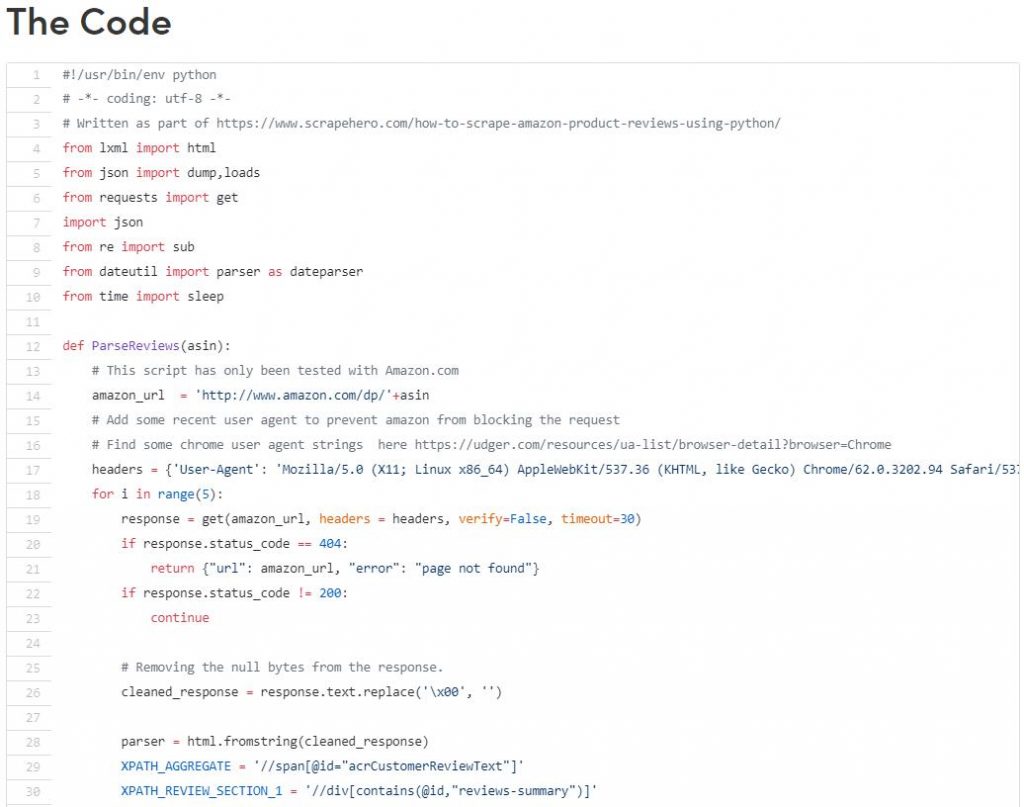
It appears to be plug and play, except for where the user must enter the specifics of which products they want to scrape reviews from. Be sure to read all lines that begin with #, because those are comments that will instruct you on what to do. For example, when it says,
‘# Find some chrome user agent strings here https://udger.com/resources/ua-list/browser-detail?browser=Chrome, ‘
it’s advised to follow those instructions in order to get the script to work. Also, notice at the bottom where it has an Asin list and tells you to create your own. In this instance, get an Amazon developer API, and find your ASINS. each of the products you instead to crawl, and paste each of them into this list, following the same formatting. Following this, and everything else, it should work as explained.
