

The Beginner’s Guide to Web Scraping with Python & Scraper Tools
A rundown of what you'll need for Web scraping, what you might need When Scraping with Python & software, and what you don't need.
Web scraping is the great shortcut for anyone looking for a large amount of data from specific websites. The term ‘Web scraping’ encompasses the use of a ‘crawler,’ which is something that can navigate from webpage to webpage, and even subpage to subpage within a webpage; ‘spiders,’ which extract data to the extent that the web owner deems legally permissible, and ‘scrapers,’ which may refer to the entire function of getting a machine to collect and store data for you.
By data, we do not mean a html file or two: scrapers can extract millions of data points in a short amount of time. Even better, they can be instructed to extract specifically the type of data that is being sought after.
This is, in many cases, how such massive datasets are built: no human can collect data at a fraction of the rate and efficiency that a machine can. This is the essence, is what data scraping is when people talk about web scraping.
But first, know that from any single personal computer, there is a steadfast limit to data scraping capabilities. The computational power needed to scrape data at an industrial level requires servers and data centers. This is also why many of the services listed below have pricing options. With the ones that don't, the barrier comes from the robots protocols,
So, before you starting scrapping, Please take “Web Scraping Protocols” seriously at first!
Web Scraping Protocols
No matter what tools you use for Web scraping, there are customary protocols websites put in place. Failing to abide by these protocols can have a few different negative results.
If the site is small enough, scraping at a high volume could impact their server could come across as a server attack, which could have legal ramifications. Medium-sized or larger-sized websites would be less susceptible to this, but there are other consequences instead.
API
If the websites, has an API, then using the API is encouraged. But scraping is more about extracting raw data from webpages, so using an API technically collects data using an entirely different method.
In any case, there are restrictions in what you can scrape, how often you can scrape, and the size of what you can scrape. As you learn about data scraping you may become familiar with the terms workers or spiders (defined later). These will need to follow those guidelines, but where can those guidelines be found?
/robots.txt.
Wherever information exists on a network of webpages under a single domain, the larger website usually has a landing page with instructions on what web scrapers can and cannot do on their websites. This information can commonly be found under the URL of the homepage, followed by a ‘/robots.txt'.
For example, Facebook, the social media network known for having more restrictions than its peers, marks all of the actions that are forbidden at facebook.com/robots.txt. Here's a snippet of some of the things they do not allow you to scrape, taken straight from their own ‘robots.txt' subpage. This is also a good place to check if the website contains a sitemap. Some do, some don’t, but if there is one, the scraper’s job gets a whole lot easier.
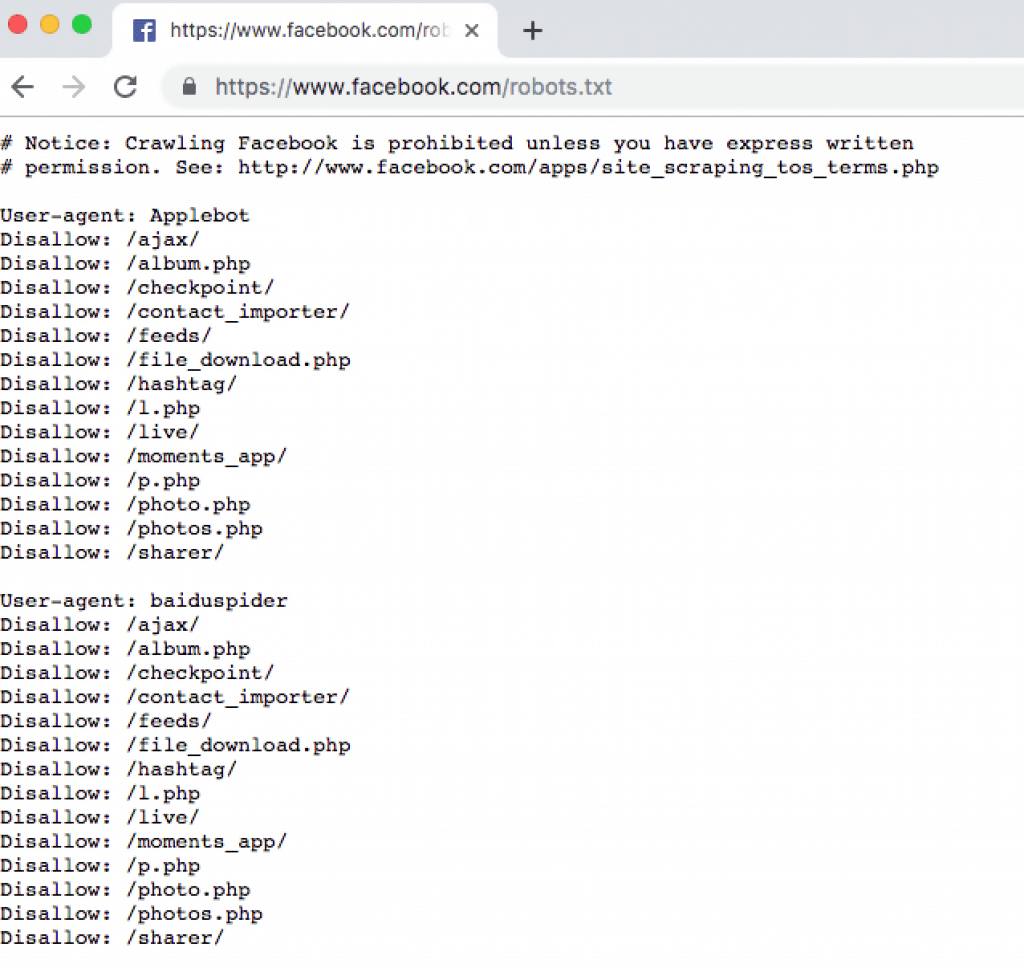
Note that this doesn't mean scraping this type of data from this particular website is impossible (or from any website, for that matter). It simply means that the administrators have made it immensely more difficult in a number of ways: easier to get IP banned, harder to use simple, popular web scraping tools, among other barriers. Of course, these things can always be circumvented to some extent with some programming chops.
IP rotation
Your IP address could get banned pretty quickly for failing to acknowledge the rules laid out by the websites. To avoid this I suggest you use rotating proxies for web scraping, Now there are lots of residential proxy services offer IP rotation for scraping and web crawling, you can easily set up IP rotation via those rotating proxies providers, let me use the Smartproxy as an example, here is an easy IP rotating code using python as the sample for beginners,
# In this example a query to `example.com` is performed from a random IP.
import urllib.request
import random
username = 'USERNAME'
password = 'PASSWORD'
entry = ('http://customer-%s:%[email protected]:7000' %
(username, password))
query = urllib.request.ProxyHandler({
'http': entry,
'https': entry,
})
execute = urllib.request.build_opener(query)
print(execute.open('https://ipinfo.io').read())
Also, Premium proxy providers like Luminati.io, Not just offer easy to use API but also offer advanced Luminati Proxy Manager (LPM) to handle the IP rotation for web crawlers and data extraction.

And there is no doubt, Luminati offer the best residential IP rotation solution for web scraping if have an adequate budget!
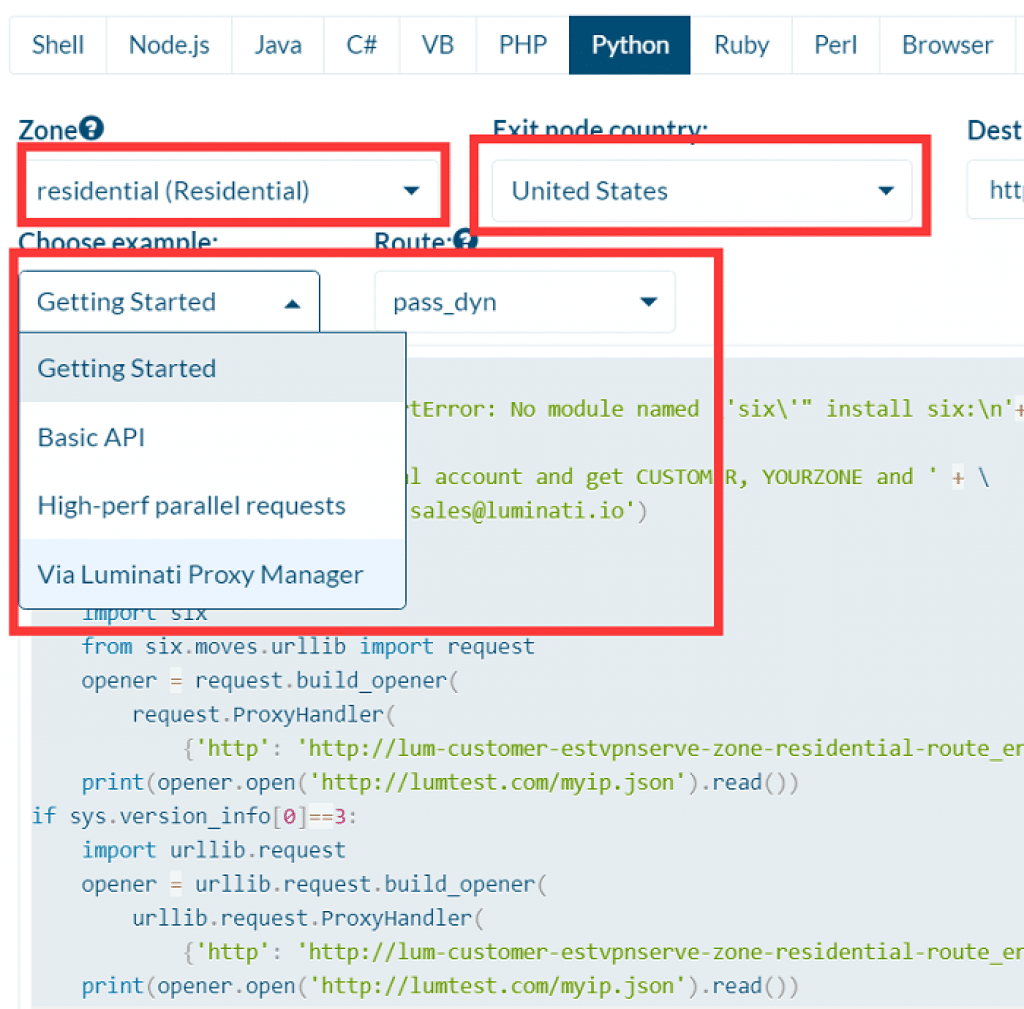
#!/usr/bin/env python
print('If you get error "ImportError: No module named \'six\'" install six:\n'+\
'$ sudo pip install six');
print('To enable your free eval account and get CUSTOMER, YOURZONE and ' + \
'YOURPASS, please contact [email protected]')
import sys
if sys.version_info[0]==2:
import six
from six.moves.urllib import request
opener = request.build_opener(
request.ProxyHandler(
{'http': 'http://lum-customer-estvpnserve-zone-residential-route_err-pass_dyn-country-us:[email protected]:22225'}))
print(opener.open('http://lumtest.com/myip.json').read())
if sys.version_info[0]==3:
import urllib.request
opener = urllib.request.build_opener(
urllib.request.ProxyHandler(
{'http': 'http://lum-customer-estvpnserve-zone-residential-route_err-pass_dyn-country-us:[email protected]:22225'}))
print(opener.open('http://lumtest.com/myip.json').read())
Read more: Top 15 working Backconnect & rotating proxies for web scraping.
back to menu ↑There are mainly two ways to scrape online, The one is using Python for Web Scraping, the other is using developed web scraper tools, let me introduce what's needed in detail.
Web scraping Toolkits and Essentials using Python
In any case, the first two packages below are incorporated into the majority of web scraping efforts in Python, I would imagine. They work together seamlessly, and both provide invaluable tasks for web scraping.
Beautiful Soup
Beautiful Soup, installable via pip or conda as ‘bs4,’ is an invaluable package for data scraping. It’s useful because of how easily can be used to manipulate the scraped data, extracting from a typical web page what is needed, and leaving out what is not needed.
As workers crawl from par to par extracting data, they need instructions on what to download. Without instructions, they’ll download the entire thing, which would be too inefficient, clunky and noisy to ever be practical.
Thus, Beautiful Soup tells a scraping tool which specific data points to extract from a webpage — for example, the entry within the cells of a column from a table.
There are far better tutorials elsewhere for those experienced in Python who wants to write their own scripts with Beautiful Soup to their preference. (Insert hyperlink). However, there are also many scripts publicly available for common extractions made on a HTML/CSS/JS webpage.
Requests
If you already use Python, chances are you already have ‘requests,' installed. If not, do so immediately because its usefulness is remarkable, even outside the scope of this subject. In short, requests allows you to interact with web pages in a number of useful and flexible ways.
Requests can interact with webpages, crawl an entire sitemap of a certain webpage, and even log in when prompted, as Beautiful Soup extracts the necessary data. It’s the script’s tour guide to the internet: taking it where it needs to go, granting it access to places it could not get to on its own, and moving from place to place as needed, providing information on the site and sitemap all the while.
Parcel
The parcel is like Beautiful Soup in functionality with data scraping. Simply put, It directs the scraper to the piece of data it wants, just as Beautiful Soup does. It claims to fame is that it can automatically navigate through XPath and other common CSS containers where data is often hidden.
Beautiful soup can do this too, however, with Beautiful Soup, the script has to be written so that Beautiful Soup knows where to find data hidden within Xpath.
You only have to find one example of data within Xpath on a webpage, but it requires right-clicking the page, clicking ‘inspect element', and going through the divs in order to find where one example of the data is hidden under. Here's an example of a script I wrote doing just that, where I actually did have to use Selenium(discussed later):
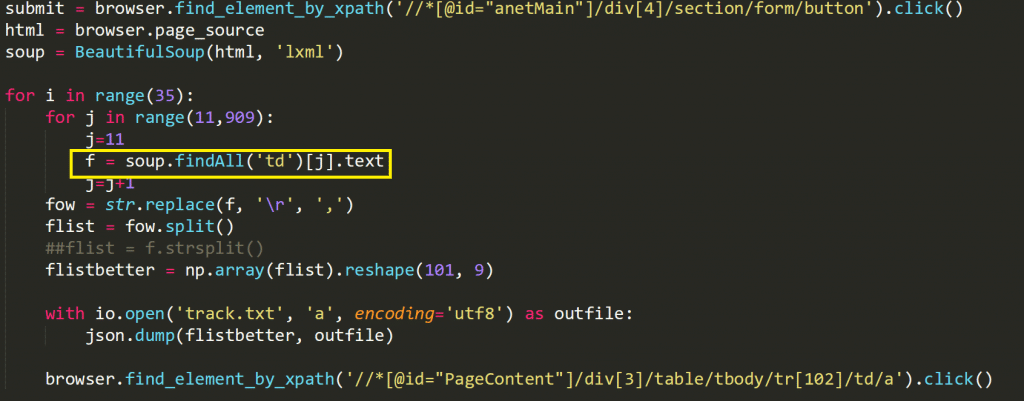
That ‘td' was where the data was hiding under an Xpath ‘tr.' Once I found that, the soup did the rest.
However, Parcel can skip the step of first finding the element, because it can do so on its own, according to this section of its documentation. What appears to necessarily be the case is that the package is bulkier than Beautiful Soup, and may cause slowdowns, but it offers a great deal of more functionality.
It may be better for beginners, although Beautiful Soup is fairly simple as well. Try both and see which one suits you. But for starters, here's a publicly available crawler demo using requests and Parcel.
Better yet, here's a site with a number of links to scripts using and explaining Parcel. Since Beautiful soup has been around for ages, there aren't as many ready-made allocated scripts as it's found here.
JSON
JSON as a Python package all likely be the most efficient way to save the scared data. The ubiquitous ‘pandas’ package offers the same functionality and deserves mention here as well. Using the built-in ‘re’ package, the script will need to write the scraped data to a file and save that file somewhere on the computer.
Selenium
Selenium is clunky and inefficient but can serve an important purpose if a web page is written in a way that the programs previously mentioned don't understand. Selenium isn’t a scraper of any kind, but can be used for navigating a scraper to where it needs to go in a pinch. Selenium is a web browser condensed into a Python package.
It requires a driver, usually a ChromeDriver, which is the Google Chrome browser it'll use. What this means is that when you run a script using selenium, a browser of your choice automatically opens, and can click certain parts of the page, enter keystrokes into certain forms, among other things, all on its own.
It’s very cool to watch, but for web scraping, its main purpose is to navigate the web scraper to a certain area of a webpage where the desired data is located. It’s an if-all-else-fails sort of mechanism since the packages aforementioned can handle the majority of web pages.
Related: Why do you require proxies for Selenium?
Scrapy
The problem with many of these tools is that they can be a hassle. With Scrapy, Visual Studio 14.0 is required, which you can get by downloading Visual Studio Build Tools. Extended requirements like these increase the odds of encountering difficulties.
The specifics of the programming environment, each of its packages, and whatever machine or server you’re working with can affect compatibility. Note, however, that Mac and Linux have no problem downloading Scrapy with PyPi. If you’re unfamiliar with this process, here’s what your terminal should look like:
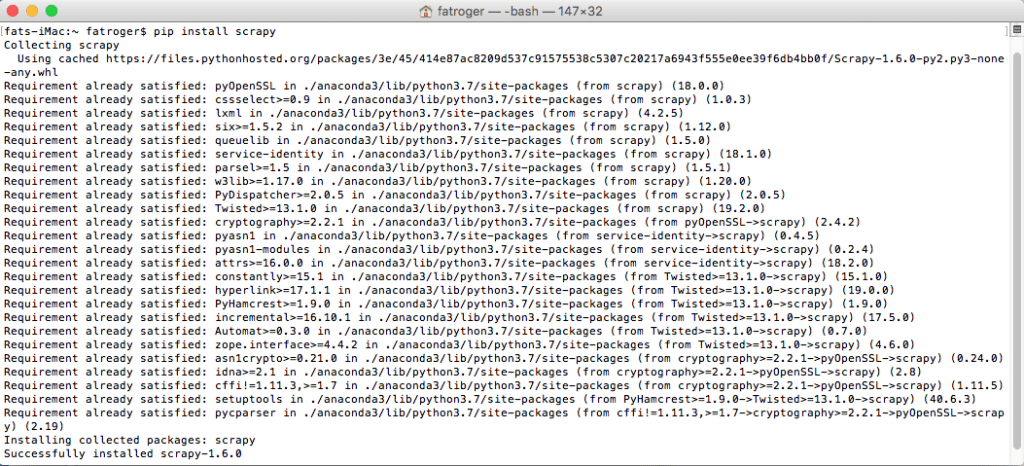
Scripts that take advantage of Scrapy’s built-in crawling and data wrangling tools can be found all over Github, Stackoverflow, and public resources. Many of them, in fact, most of them, might not be as simple as running them from a terminal right out of the box. Therefore, for non-programmers, or for programmers on hiatus, the software can come in handy,
Related: Installing Python for Reddit scraping
back to menu ↑Scrape Data using Web Scraping software Tools
There are a few different types of web scraping software tools out there to fit certain needs. Some require a little programming knowledge, while others will require none at all.
Some will have larger capabilities than others (for example, scraping multimedia, i.e. PDF, images, audio and video files). Let's go over some of the more popular tools available.
Orange - Free Open source web scraper
Orange, the free data mining site found here as well as on Github, is personally my favorite tool when it comes to scraping from particular sites like Twitter.
Its main menu is a visualization of the roadmap in which you will build and implement the entirety of the process. Here’s an example of the workflow for one data mining project I did, just to illustrate the organizational capability of the software.
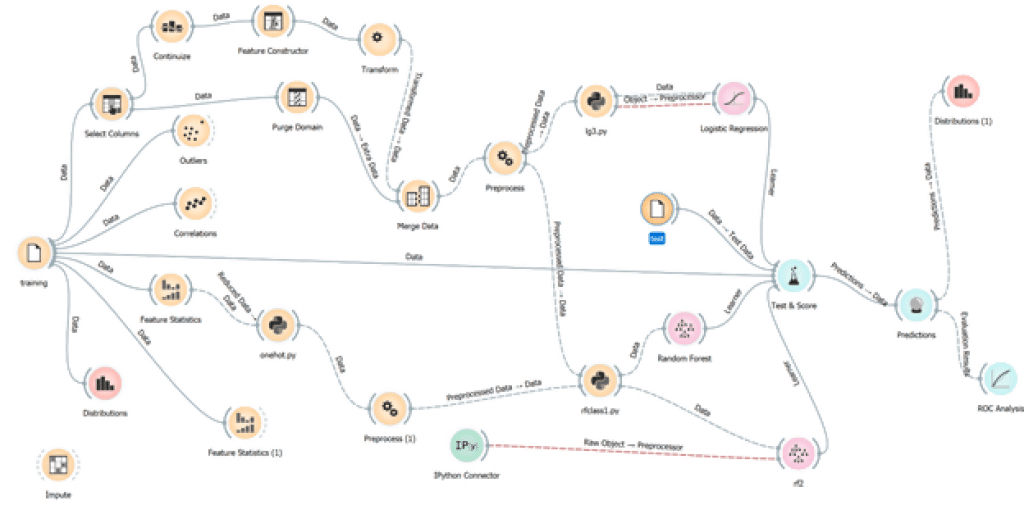
Using Orange for data scraping comes with a few benefits. First, storing, processing, and saving the data becomes incredibly simple. Short and informative trials are publicly available with instructions on how to do this. The software must abide by the terms of conditions of third parties, which is a burden when it comes to web scraping.
With scraping Twitter, for example, you will need an API key — find out how to get one here (anyone can get one), but using API limits the amount of data allows for scraping over a certain amount of time. An advantage, on the other hand, is that Orange allows their users to implement any script they’d like into the workflow, so everything mentioned above can be incorporated into Orange.
In the software, you will find an option to download extensions, including a data scraping extension. After you do that, scraping becomes as simple as adding the widget to your workflow.
Octoparse: freemium web scraping program
Octoparse is a mostly-free web scraping program available to every major OS. Since it offers premium packages to industries that can afford them, the software is excellent at what it can do.
>> Download Octoparse for free
Unlike other software that's free for a very very limited amount of scraping power, Octoparse offers a generous package to it's free users: unlimited pages per crawl, 10 crawlers at a time, and 10,000 records per export.
The number of records is the make-or-break limit to the free plan: depending on the project, 10,000 entries could be either more than enough or nowhere near enough.
Regardless, it's as effective as the Python packages listed above, and perhaps even more so. Their product overview does not exaggerate its capabilities. Just be aware of the limitations.
Paid web scraper tools
There is web scraping software that's easy to find, but not easy to stomach paying for. These programs are suitable for businesses. The pricing is exorbitant for an individual project, but you do get what you pay for, such as,
- Import.io
- mozenda.com
- heliumscraper.com
- ParseHub.com
All get rave reviews, but all cost a pretty penny. Since I have no experience with them, I will not cover them, but the choice is yours. Just know they are out there.
Beware: 100% Free Web Scraping software almost never do as promised!
The most professional, iciest, and competent methods of web scraping is to do t using hand-programmed scripts using a machine with a server or GPU with high computational power. There are hundreds of data scraping programs out there, just see a quick search on Sourceforge:
If the descritis programs like these bast capabilities that seem unrealistic, chances are they are unrealistic. Always check if there are healthy, recent and recent updates, whether the reviews back up what the developers say the software can do, and that there are a healthy number of weekly downloads. These programs that don’t pass such criteria are probably not malicious, but they may just turn out to be junk.
So, there are two routes to take with regard to web scraping, crudely speaking. The programming, scripting route, which offers more freedoms, more personalization, and more customization. Then there are software routes, which offers ease-of-use and extra computing power.
The viability of either option depends on the amount of programming one wishes to do versus the amount of paying out of pocket one wishes to do. As discussed, this is inevitably the case with web scraping software that actually works.

Python is no doubt one of most popular method for web scraping but there are some advantages in Ruby.